
Data Contracts - Putting Data Governance into Practice
“Standardized Data Products With Contracts Prevents Chaos.”

Data Contracts are still evolving with an ecosystem around. Read what Gartner thinks about and make it round wit expert insights from Dr. Simon Haarer.
The Gartner Insights
Probably somewhere in your organization, there is a data contract. It probably lives in Confluence or Notion. It describes what a data product contains, who owns it, what quality guarantees it carries, and what the rules of engagement are for downstream consumers. It was written by a data steward, reviewed by someone in architecture, and signed off in a governance committee meeting that most attendees have since forgotten.
It is not enforced. Not automatically, not at runtime, not ever.
Gartner’s 2026 Data & Analytics Summit research found that only 32% of organizations have granular governance policies - and that number refers to policy existence, not policy enforcement. The gap between “we have a data contract” and “our pipeline actually checks it” is where billions of dollars in poor data quality and AI model failures quietly accumulate. The 2026 Summit’s argument is that this gap is no longer acceptable - and that the infrastructure to close it has finally arrived.
What A Data Contract Actually Is
A data contract, at its core, is a formal specification of the terms under which a data product can be consumed. It is platform-neutral and policy-as-code-based - meaning it is not prose in a wiki but a machine-readable artifact embedded in your data infrastructure. It defines quality indicators, access rights, legal terms, versioning, lineage, and the use cases the data is certified for.

Gartner’s framework identifies three types of data products that use contracts:
Source-based - raw operational data with defined freshness and completeness guarantees
Master-data-based - curated reference data (customers, products, suppliers) with certified accuracy
Insights-based - analytical outputs where the contract governs how results may be used downstream
The critical word in that definition is enforces. A data contract that sits in documentation is a data policy. A data contract embedded in a pipeline is a guardrail. The distinction matters enormously - and it is exactly the distinction most organizations are still getting wrong.
The Infrastructure That Changes Everything
The reason data contracts are having a genuine moment at the 2026 Summit is not that the concept is new. It is that the infrastructure to actually enforce them has finally matured.
The practice Gartner calls DataGovOps makes this concrete: it embeds governance policies and controls directly into data pipelines through automation, replacing manual checkpoints and reactive audits with enforcement at runtime.

The canonical pipeline illustrates the shift:
Align → Qualify → Govern → Certify AI-Ready
At each stage, Policy as Code translates what used to be guidelines into machine-executable rules. Gartner identifies six governance domains that can be encoded this way:

The organizational implication is significant. Gartner describes the evolution this way:
Documentation-driven → Behavior-driven/tech-enabled → Technology-enforced behavior controls
Most organizations sit in stage two. The best-practice goal is stage three - where governance is not communicated to humans who may or may not comply, but enforced by systems that have no choice. The landmark of this shift: an organization where a data consumer simply cannot access a data product that violates the contract’s terms. Not because a steward caught the violation. Because the pipeline rejected the query.
Federated Architectures Made Contracts Unavoidable
The structural urgency behind data contracts comes from a trend that has been building for several years: the move to Data Mesh and federated data management.
Federated data management distributes data ownership to business domains — giving teams the autonomy to build and publish their own data products rather than routing every request through a central team. Organizations with federated data management are 3x more likely to deliver real business value, according to Gartner’s research. But federation without standardization is chaos.
“Standardized Data Products With Contracts Prevents Chaos.”
- Gartner D&A Summit 2026
When twenty domain teams each publish data products without a common contract standard, downstream consumers face incompatible quality guarantees, inconsistent schemas, and undocumented lineage. Data contracts are the mechanism that makes federation work - they provide the interoperability layer that allows decentralized production and centralized trust to coexist.
This is also why the Open Data Contract Standard (ODCS) is gaining traction: a platform-neutral YAML specification that allows contracts to travel across system boundaries and be interpreted by any compliant pipeline. It is the data equivalent of what OpenAPI did for REST interfaces - a machine-readable contract that any system can verify, regardless of which tool generated it.
AI Agents Made Contracts Urgent
If federated architectures made data contracts necessary, autonomous AI agents have made them urgent.
When a human analyst queries a dataset and finds something wrong, they typically notice. They check with the data steward. They flag the issue. The loop closes slowly, but it closes.
When an AI agent queries a dataset to make an automated decision - pricing a product, approving a credit application, routing a patient - there is no human in the loop to notice the anomaly. The agent executes on whatever it finds. Gartner’s research on Runtime Trust asks the governance question that cuts to the core: “When an AI-generated insight is wrong - who signs their name under it?”
Runtime Trust is the capability to monitor, validate, and control AI agents during their actual execution. And the prerequisite for runtime trust is that the data an agent consumes carries a verified contract - a machine-readable specification that the pipeline checks before the agent gets access.
Thirty percent of GenAI projects fail due to poor data quality. Not due to model failures. Not due to prompt design. Data quality. If you are deploying AI agents without verified data contracts at the access layer, you are not running AI governance. You are running AI gambling.
Prototype-First: The Answer To Governance Theater
The governance theater objection is real. Anyone who has sat through a data stewardship program that produced beautifully formatted policy templates and zero behavior change understands why practitioners are skeptical of governance initiatives.
Gartner’s Prototype-First Governance model is a direct answer to this skepticism.

Rather than requiring full contract coverage before any data product can be published, it structures governance requirements progressively:

The critical success factor is having clear criteria for transitioning between stages. Without them, use cases stagnate in sandbox indefinitely and governance never scales. But the model removes the most common blocker: the expectation that governance must be perfect before innovation can begin.
This reframes the data contract from a barrier into a maturity milestone. A team publishing a new data product does not face an all-or-nothing governance requirement. They face a progressive ladder - and the contract grows alongside the use case.
The Reframe: Contracts Are Infrastructure, Not Documentation
Here is the shift that changes how to think about data contracts: they are not governance artifacts. They are infrastructure.
When you think of a data contract as a governance document, you optimize for completeness and sign-off. You run it through a committee. You file it. It ages.
When you think of a data contract as infrastructure, you optimize for machine-readability and enforcement. You write it as code. You test it. You deploy it into your pipeline. You version it. You monitor drift. You treat a broken contract the same way you treat a broken API - as a production incident, not a process violation.
Gartner’s observation that “the best governance is invisible” is really about this: governance embedded in the pipeline disappears from sight precisely because it works automatically. The data steward is no longer the last line of defense. The pipeline is.
What this means in practice
The quality of your AI agents is bounded by the quality of your data contracts. An agent has no independent judgment about whether the data it receives meets quality standards. That verification has to happen upstream, at the contract enforcement layer. If your contracts are advisory, your agents are flying blind.
Policy as Code is the path, not the destination. The six governance domains Gartner identifies - definitions, quality, security, privacy, lifecycle, ethics - cannot be reliably enforced by humans at scale. Organizations that have not started translating governance policies into executable code are accumulating technical governance debt that grows more expensive with every AI deployment.
Producer-Consumer accountability needs to be explicit and structural. At Lloyds Banking Group, with 800+ AI models in production and 28 million customers, the distinction between data producers (who define and control quality rules) and data consumers (who adhere to them and report deviations) is what makes quality accountability possible at scale. The accountability gap - “everyone’s responsible, so no one is” - is a leadership problem before it is a technology problem.
Start with the use cases that hurt most, not the ones that are easiest to document. Outcome-Driven Data Governance research consistently shows that governance initiatives fail when they are disconnected from business priorities. The data contract that is worth writing first is the one protecting the data product that, if wrong, would cause the most visible business damage. That is also the one most likely to attract funding for the infrastructure to enforce it.
The Question Worth Asking
Data contracts are not a new idea. What is new is the enforcement infrastructure - DataGovOps pipelines, Policy as Code tooling, open standards like ODCS, and the urgency created by autonomous AI agents that consume data without human oversight.
The organizations that will govern AI effectively are not the ones with the most comprehensive governance frameworks documented in their knowledge management systems. They are the ones that have figured out how to enforce governance at the speed of their pipelines.
If your organization’s data contracts were machine-readable and pipeline-enforced tomorrow, what percentage of your current data products would pass? The answer to that question tells you more about your AI readiness than your architecture diagram does - and it is usually a number that prompts a very productive conversation.
The Expert Talk
Insights from the Interview with Dr. Simon Harrer, Entropy Data (Data Contract Manager)
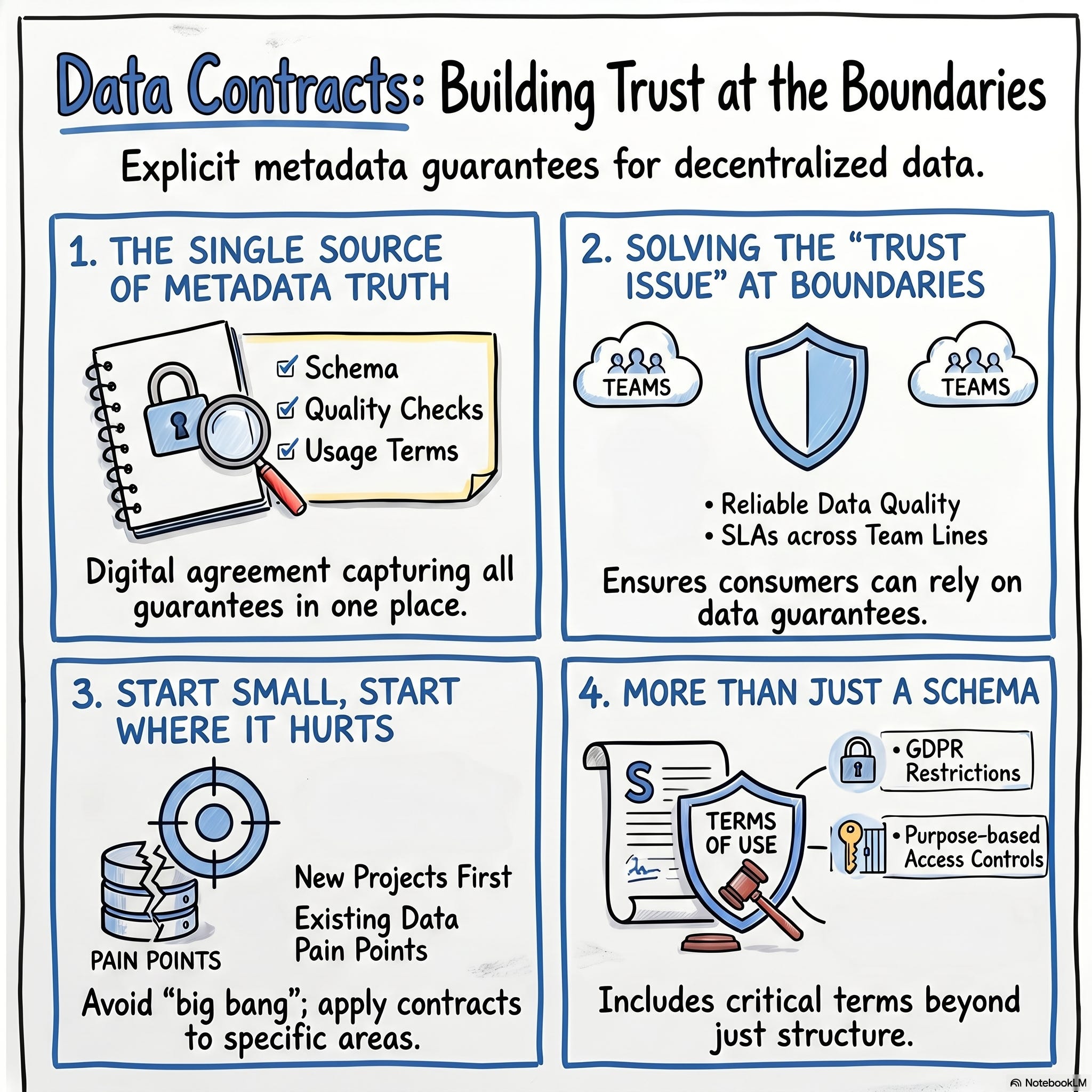
Single Source of Truth: Data contracts act as a unified source of truth for metadata, combining data validation, documentation, and protection into one framework. - "I think data contracts combine a lot of those approaches into a single let's say single source of truth of meta data for no protecting specifying a data set someone shares"
Establishing Trust at Boundaries: In decentralized data architectures, contracts are essential tools to establish explicit trust between different teams. - "you have a lot of team boundaries and precisely at these team boundaries you need to establish trust and data contracts are basically the tool to make that explicit"
Comprehensive Metadata Components: Beyond just schemas, a data contract includes quality checks, service level agreements (SLAs), and clear terms of use. - "it contains... the data schema... data quality checks in SQL or using libraries... service level agreements like latency... and you can define terms and use terms of use"
Pragmatic Implementation: The most effective way to adopt data contracts is to avoid over-engineering and instead focus on specific areas where there is friction or new development. - "My suggestion would be just start small start where it hurts or start where you build something new because then you try it out learn and you immediately have value with the contracts"
Defining Ownership: Data contracts solve the "ownership problem" by identifying the party responsible for the data's reliability and quality guarantees. - "if you find someone who says I'll take responsible for the data I'll be held responsible for the guarantees in the data contract then you have solved the ownership problem"
AI and Semantic Evolution: Future data contracts will provide verified context and semantic definitions to help AI models query and understand data more accurately. - "contracts are already great for AI because they they contain so much important metadata... we see a lot of um uh requests to say let's put in additional context for AI"
A Binding Promise: While often appearing one-sided at first, they are considered "contracts" because they represent a binding promise from the provider to the consumer. - "it's contractual because I promise that and I will hold up to my promise So that that contractual part is is still valid"
You want to see or hear more about Data Contract from Simon, have a look here.
Do you already use Data Contracts in your organization? What is your experience?
data contracts before they reach the model is exactly the missing layer. i sample 5% of citations my llm produces and audit them manually – about 20% are subtly wrong. contracts catch the upstream drift before it becomes a downstream hallucination. question: what's your sampling strategy for catching bad inputs before they hit production?