
Databricks Data Lakehouse in a SAP Ecosystem for Data & Analytics
Thinking in options and synergies

The Data Lakehouse can be seen as a evolution in data architectures over time, through progressive unbundling of the classic database in a cloud-native context. While the term “Data Lakehouse” was already mentioned in 2017 for Snowflake, Databricks started from around 2020 to promote the concept and took the data world by storm.
Typical key componentes of the (Open) Data Lakehouse are:
File Formats like Parquet, ARVO or ORC for data storage, offering column store, partitioning, data compression, open source and others depending on the different formats every one has pros and cons - for the Data Lakehouse from my observation Parquet became the de-facto standard.
Open Table Formats like Delta Lake, Apache Iceberg or Apache Hudi, offering indexing, time travel, schema enforcement and evolution, ACID transactions and more - for the Data Lakehouse depending on the vendor Databricks created and use Delta Lake, while Snowflake, AWS or Dremio seems to support Apache Iceberg which could become the de-facto standard, while others may prefer Apache Hudi.
Metastores (Technical Catalog) offer technical metadata to make SQL work on a object store. While Databricks used Hive Metastore which is now shifted to their Unity Catalog, Hive was for a long time kind of standard here. LinkedIn just open sourced OpenHouse and Tabular seems to show a strong supported of Apache Iceberg. These catalogs are not to be confused with Data Catalog used for Data Governance and Data Discovery.
MPP SQL query engines like Trino/Presto or Photon1 (Databricks), offering the necessary performance to process the data for ETL or BI workloads. MPP (Massively Parallel Processing) is not new and well known implementations in the Big Data World are Apache Hive or Impala. If you need performance for data transformations or queries you still need parallelization on a distributed compute framework to crunch unlimited amounts of data. Besides open source implementations like Trino/Presto, vendors implemented their own like Databricks created Photon in 2022. While Apache Spark makes here a big step to accelerate former big data queries, and Databricks was build on Spark originally, today Photon is the default engine for many tasks.
Typically these components are based on a object store/data lake technology to form what we call a “Data Lakehouse” today.

Fig. 1: The Data Lakehouse idea
Bringing both sides together promises capabilites from both sides like managing schemas or supporting Governance, while having a high flexibility in data usage.
What makes Databricks such a strong solution?
Databricks today is much more than a optimized cloud environment for Apache Spark. Over the time they build a end-to-end data service and currently excel in topics like GenAI and others.

Fig. 2: Databricks architecture2
Typical advantages of Databricks are a single data repository, simplyfing BI and ML use cases, reduced data storage costs (compared to RDMS), less data transfer and redundancy and support for ACID-compliant transactions on a data lake infrastructure.
The Databricks Data Warehouse approach built on the new Photon engine, which similar like Spark, what is still available represents a distribute computing approach, to make use of cloud scalability and the serverless approach of Databricks.
Databricks and SAP Data & Analytics
In my former blog I described in general the aspects of why solutions of MDS and Best-of-Suite vendors like SAP can come together into a data ecosystem for deliver on the value of data.
A general scenario for the integration can be seen in the following picture. There are several ways how SAP Datasphere (or similar for SAP BW) can play together. From an SAP perspective SAP can directly access the data lake (here Azure ADLS2), data can be orchestrated via SAP Data Intelligence (Cloud) or the connectivity and libraries can be used to create a data federation/data fabric approach by accessing the powerful Databricks engine and make use of there possibilities for accessing big data or federate machine learning.
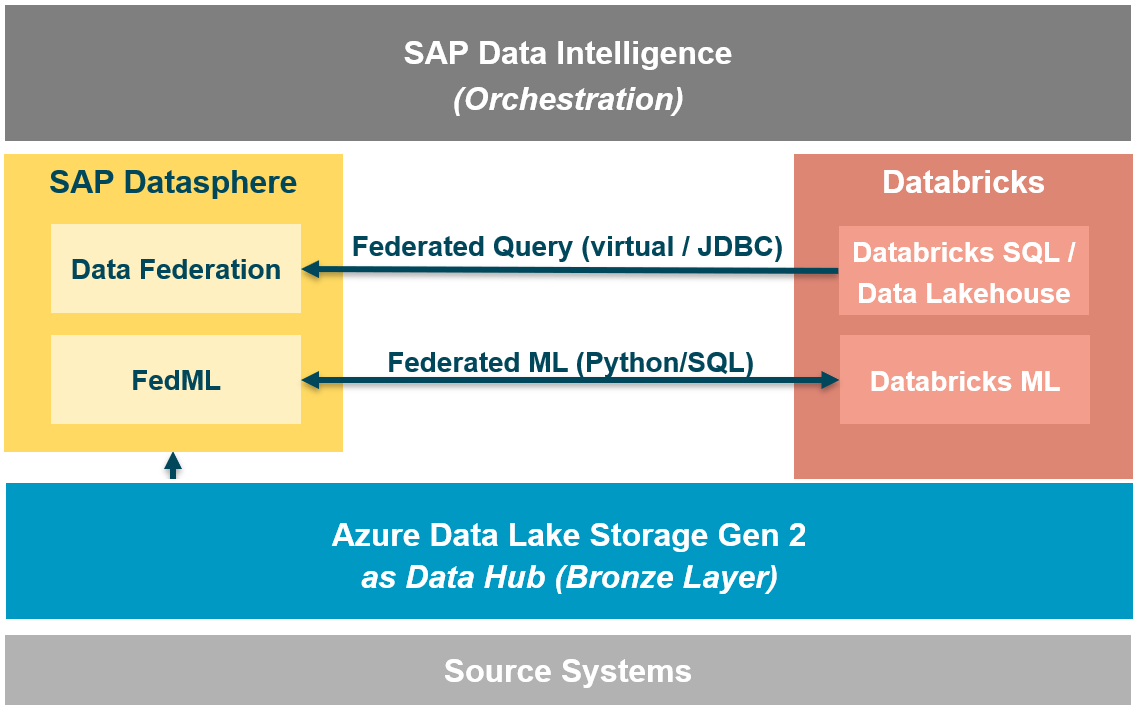
Fig. 3: General integration architecture of SAP Datasphere and Databricks Data Lakehouse
To dive a little bit deeper I show a more detailed ML scenario. there are several options by using services from the SAP Business Technology Platform (BTP) wich is SAPs PaaS solution running on the same Hyperscalers as Databricks. While BTP is also the base for the SAP data solutions like SAP Datasphere and SAP Analytics Cloud, for machine learning you can use Kyma for container/Kubernetes services to support the deployment and scalable serving of ML services.
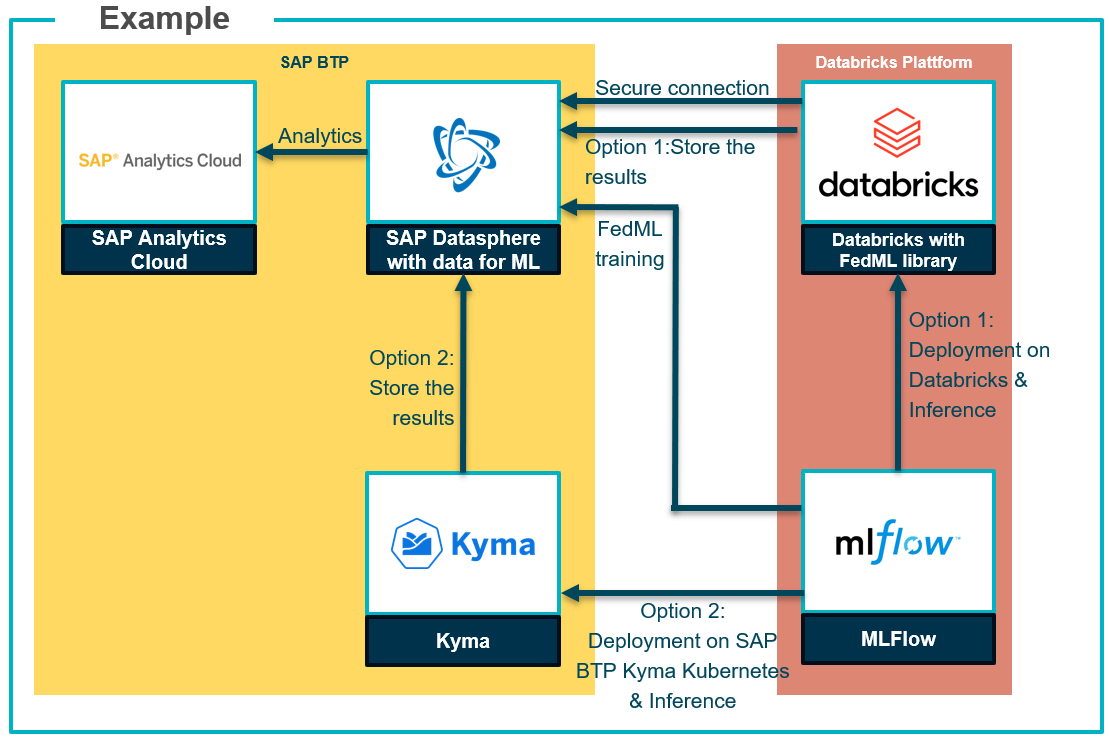
Fig. 4: Example implementation scenario for Databricks with SAP Business Technology Platform (BTP)
In a data ecosystem many services can play together or extend the capabilities of central components to better adapt to the use case and capabilities needed. You can also adapt better to the typical environment different roles work at and can perform best.
A Practical Use Case
To come down to reality, I will show a use case based on a practical example we described in our whitepaper about SAP & Modern Data Stack.3 We called the scenario “Federated Machine Learning for Sales Forecasting in B2C”, as we observed several similar situations on customer side. Therefore this can be build upon the idea presented above. The Use Case can be described as follows:
Powerful prediction of sales data based on internal and external data.
Data in SAP Datasphere comes virtually from S/4HANA, data in Databricks Data Lakehouse comes from other non-SAP systems and external sources.
Supplemented by weather data via a corresponding (external) data product from the SAP Datasphere marketplace.
Use of consolidated master data (e. g. from S/4HANA integrated Master Data Governance) in SAP Datasphere for enrichment for delivering comprehensive reporting of budgeted and actual sales figures.
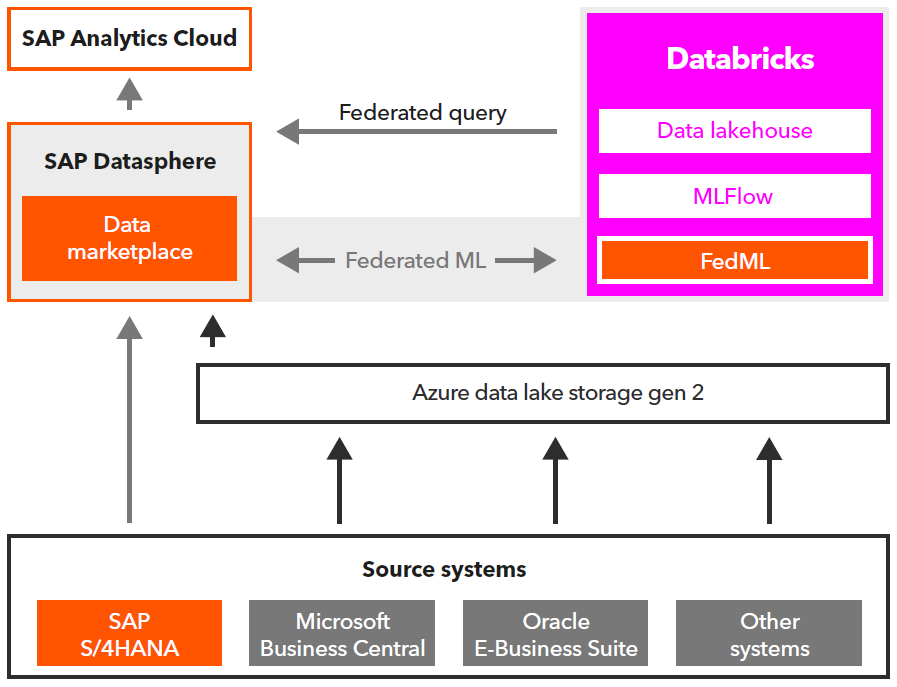
Fig. 5: Integrating SAP Data & Analytics with the Modern Data Stack based on Databricks
Some key aspects of this use case are having a federated scenario without duplicating the SAP data in Databricks. Data scientist works in a familiar Databricks notebook environment and ML models for new predictions can be provided in a Databricks or SAP Kyma environment.
Benefits of this scenario can be seen as follows:
Optimization of user experience and acceleration of exploratory analysis and prototyping for data scientists.
Expansion of options for data platforms and their functions, such as machine learning or big data processing for different use cases, while reducing data duplication at the same time.
Leveraging Business semantics and governance from there source systems, especially for the SAP ecosystem.
We see here that both platforms work together but leverage optimized integration of their specific ecosystems. There may be other solutions and ways to bring these data together as shown above as SAP Datasphere also supports based on their HNA technology and supports a Data Lake Relational Engine for big data handling while just transfering data from SAP systems to Databricks is also a common szenario.
This is possibly only on solution and decisions for a long term architecture should be based on a larger context. But the goal of this article was to raise awareness about possible data ecosystems in todays complex data world.
What is your experience with data ecosystems and the integration of SAP D&A and Databricks Data Lakehouse? Which experiences do you make and which other ways are you possibly using?
https://people.eecs.berkeley.edu/~matei/papers/2022/sigmod_photon.pdf - Paper “Photon: A Fast Query Engine for Lakehouse Systems“