
Discussing Master Data Management
Key Debates and Emerging Realities from Malcolm Hawker

Master Data Management (MDM) has evolved from a "nice-to-have" to a "must-have" for many organizations, acting as the connective tissue that binds disparate functional silos and enables crucial cross-functional collaboration. However, its implementation and underlying principles remain subjects of ongoing debate and misunderstanding within the data community. This article explores several key controversial topics, contrasting traditional viewpoints with a more adaptive and pragmatic perspective.
Master Data Management (MDM) is a set of processes, governance practices, and technologies used to create and maintain a single, consistent, and trusted source of an organization’s critical business data — such as customers, products, suppliers, and locations — across different systems and departments.1. The "Single Version of the Truth": An Enduring Ideal or a Flawed Pursuit?
The notion of a "Single Version of the Truth" (SVOT) has long been a foundational concept in MDM, aiming for one definitive record for critical entities like customers or suppliers. Many organizations, however, struggle to achieve this singular, all-encompassing truth, leading some to declare the SVOT concept, and by extension MDM itself, as "dead".
SVOT is not dead, but its definition must be refined: "truth is contextually bound". While different departments, such as marketing and finance, may hold distinct "truths" about an entity based on their specific functional needs, there must always be a single answer within a given context. For example, if the CFO asks for the total number of customers, there can only be one definitive answer. MDM, therefore, needs to manage these multiple contextual truths and provide mechanisms to reconcile them when an enterprise-wide view is required. This adaptive approach to managing truth necessitates an equally adaptive data governance framework capable of defining and enforcing policies for various contextual truths. The challenge lies in moving from managing one set of business rules to potentially "N sets of business rules".
2. MDM Implementation Styles: Simplifying Complexity and Debunking Myths
Traditionally, Gartner identified four MDM implementation styles: Consolidation, Registry, Coexistence, and Centralized. Functionally, there are only two primary styles: analytical MDM and operational MDM.
• Analytical MDM focuses on creating a 360-degree view by linking existing data from multiple sources without altering current business processes. It's less disruptive, faster to implement (weeks, not months), and ideal for providing consistent reporting.
• Operational MDM aims to create a "gold master" record that is pushed back into source systems, effectively making the MDM hub the system of record. This style delivers the highest value but is also the most disruptive and technologically demanding, requiring significant changes to business processes and robust data governance. Starting with analytical MDM to deliver quick value and then evolving to operational MDM over time.
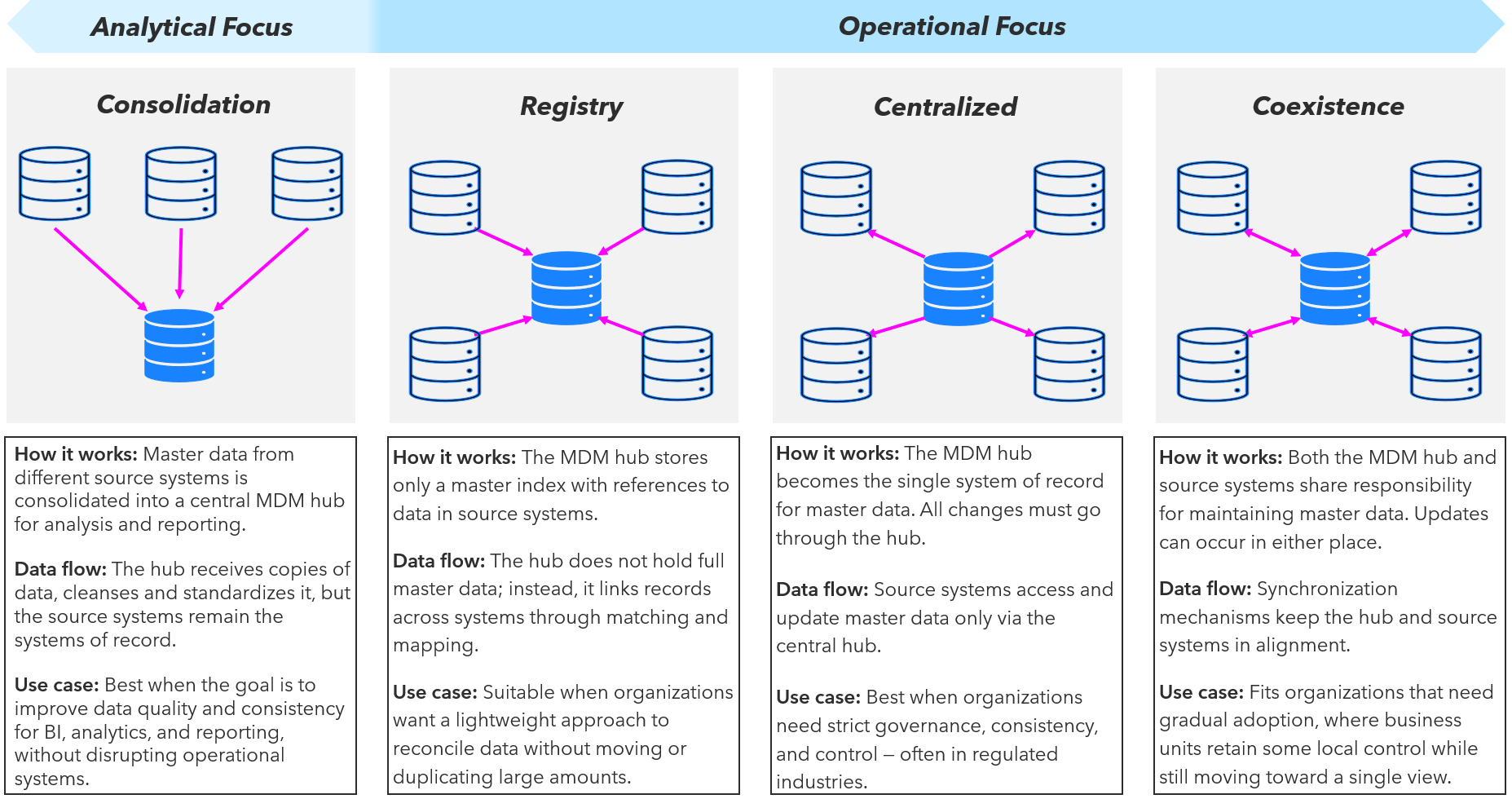
Abb. 1: Master Data Management Implementation Styles
A particular point of contention is the "Registry" style, a rather "theoretical construct" rarely seen in practice due to its "unnecessarily complex" nature and being beyond the maturity of most organizations. This style might only become viable in a future state where AI automates most of the data management burden. However, this view is not universally shared. This approach, which links records without physical replication and preserves source system integrity, has been vital in regulated industries like healthcare and government where data replication of sensitive information is often prohibited. While effective for compliance and decentralized data ownership, it is generally considered architecturally unsuited for analytical use cases. The "Centralized" style as functionally diminishing for individual domains, though it remains valid for managing reference data. The architectural choice is paramount, as a misstep can undermine strategic initiatives like mergers and acquisitions.
3. The Role of AI in MDM: Hype, Reality, and Future Automation
The emergence of AI, particularly generative AI (GenAI), has sparked intense debate about its impact on MDM, leading to an "AI hype versus AI reality".
Classic AI (Machine Learning/Natural Language Processing): MDM provides immense value for traditional AI. By delivering trusted, accurate, and consistent structured data, MDM significantly reduces the data preparation burden for data scientists, enabling more effective machine learning and natural language processing applications.
Generative AI (GenAI): The direct impact of MDM on GenAI is currently more limited and "not that simple". GenAI primarily operates on unstructured text, while MDM specializes in highly structured data. While structured MDM data can be leveraged through advanced techniques like Retrieval Augmented Generation (RAG) patterns and vector databases to constrain hallucinations and improve accuracy in agent-based GenAI solutions, widespread adoption of highly customized GenAI deployments remains low.
Future Automation (Augmented MDM): Looking ahead, MDM is predicted to become "nearly fully automated" by AI, a concept known as Augmented MDM. This will encompass the automation of data modeling, hierarchy management, entity resolution, and data integration. Furthermore, MDM-like disciplines will increasingly be applied to unstructured data to ensure its trustworthiness for GenAI applications. This gradual shift from augmentation to full automation will eventually integrate AI capabilities into the "fabric" of MDM, making it a standard mode of operation rather than a unique feature.
4. Data Cleanups: A Prerequisite or a Pitfall?
A common misconception is that extensive data cleaning is a mandatory prerequisite for MDM implementation. Data cleanup is "not a dependency for a successful Master Data Management".
When starting with analytical MDM, prolonged and costly data cleanups are unnecessary. Organizations can "price in" a certain level of "bad data" and still achieve significant business value. The immediate priority should be to stop the influx of new, poor-quality data.
While data cleaning might be justified for operational MDM, it requires careful consideration due to its high cost and time-consuming nature (e.g., one person can clean approximately 1,000 records per month). Without addressing the root causes of data quality issues, cleanups offer only temporary relief. The focus should always be on the business value derived, not on achieving perfect data quality.
5. Measuring MDM's Business Value: Beyond Data Metrics
A significant area of debate revolves around how to measure the success of MDM initiatives. Many data professionals tend to focus on data-centric metrics such as the reduction of duplicates or improvements in data quality.
MDM programs must be measured by specific, quantifiable business outcomes and Key Performance Indicators (KPIs), such as increased revenue, reduced costs, or mitigated risks. Businesses are primarily interested in results, not merely the "bad data" itself. Data leaders need to become more "business literate" and learn to quantify the value of their data in terms that resonate with business stakeholders.
The solution involves linking data-related KPIs to business-centric KPIs, understanding customer processes, and quantifying how improvements in data translate into tangible business benefits, even if initial estimations are imperfect. Focusing on a limited number of high-priority KPIs (e.g., 5-10) can provide a clear baseline and demonstrate value effectively.
6. "Data Ownership": A Misnomer for Master Data?
The concept of "data ownership" is a cornerstone of many data governance frameworks, particularly in modern approaches like Data Mesh, which advocate for domain-based data sovereignty. However, this idea is highly debated in the context of master data.
The notion of individual "data owners" for master data to be "annoying" and a "misunderstanding". By its very definition, master data is enterprise-wide and widely shared, implying that "everyone is" an owner. The challenge arises when an enterprise-level answer is needed (e.g., the CFO asking for total customers), where fragmented "ownership" can lead to inconsistent responses.
Instead of focusing on individual owners, the emphasis should be on establishing global data governance frameworks that clearly define policy creation and enforcement across different organizational levels. This framework should delineate what constitutes global versus local data governance, and who is responsible for policy definition and enforcement at each level. From this perspective, a Chief Data Officer should "never call anybody a data owner" for master data.
These ongoing discussions highlight the dynamic and evolving nature of MDM. As new technologies emerge and business demands shift, a pragmatic, outcome-focused, and adaptive approach is crucial for successful MDM implementation and for truly leveraging master data as a strategic asset.
This text is based on differend discussions I see following Malcolm Hawker, who is discussing about Data Leadership, modern data management trends and a lot about Master Data Management.