
Human in the Loop - The Responsible Choice?
It's a Starting Point, Not a Strategy

Only 23% of organizations report confidence in their GenAI security and governance. Yet when you ask those same organizations how they handle AI agent oversight, most will tell you the same thing: humans approve every step. Human-in-the-Loop. The safe choice. The responsible choice.
The problem is that “human approves every step” applied uniformly is not a governance model. It is governance avoidance dressed up as governance rigor - a way of feeling in control without actually having made the decision about what control requires. It also, not coincidentally, tends to produce exactly the bottlenecks that make agentic AI feel like it is not delivering on its promise.
The Gartner D&A Summit 2026 and the regulatory landscape emerging around it tell a more nuanced story. Human-in-the-Loop is the mandatory starting position. But it was never meant to be permanent.
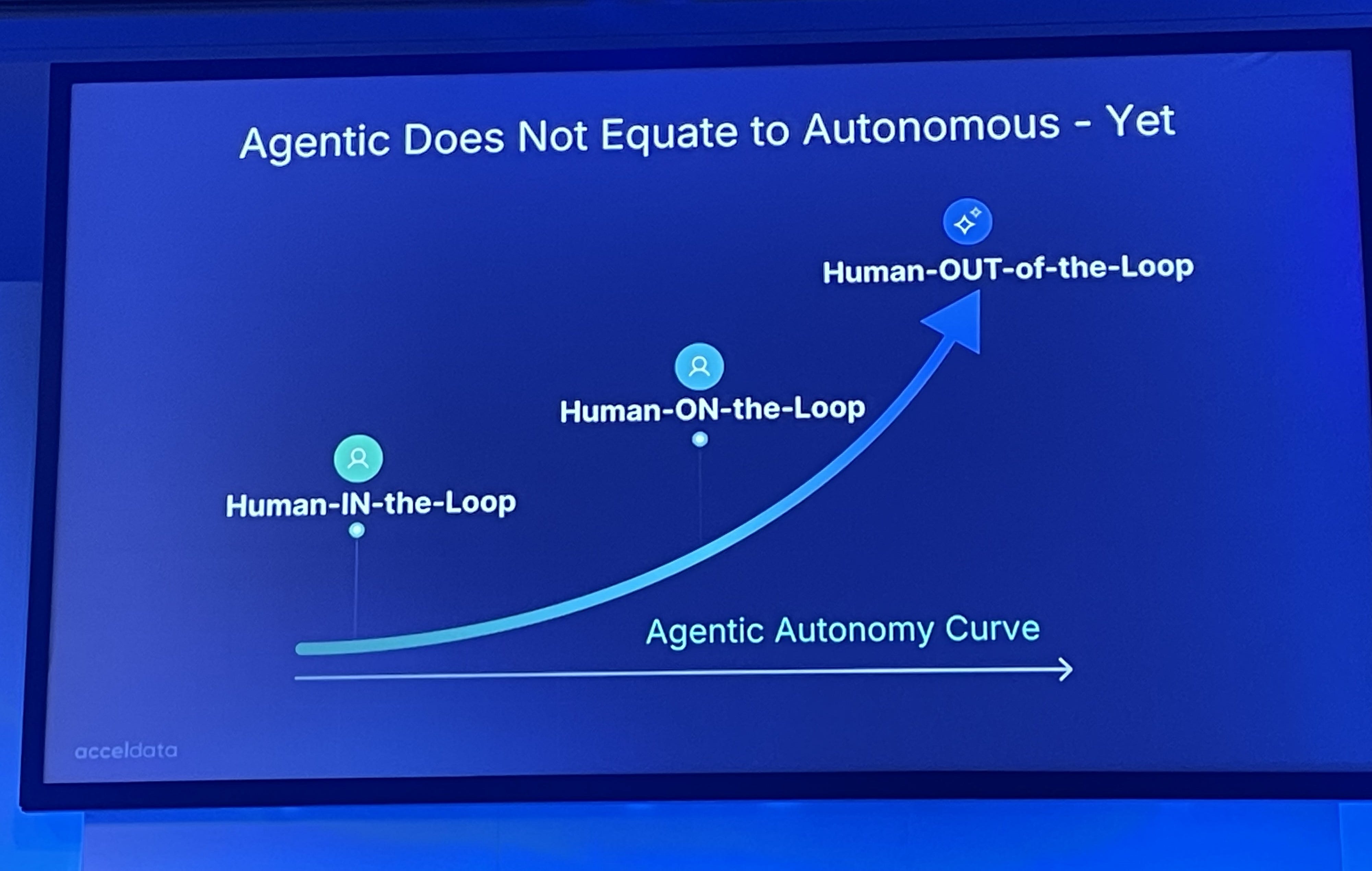
What The Three Control Levels Actually Mean
Gartner’s framework for agentic AI governance defines three control levels, and getting the vocabulary right matters because organizations frequently conflate them:
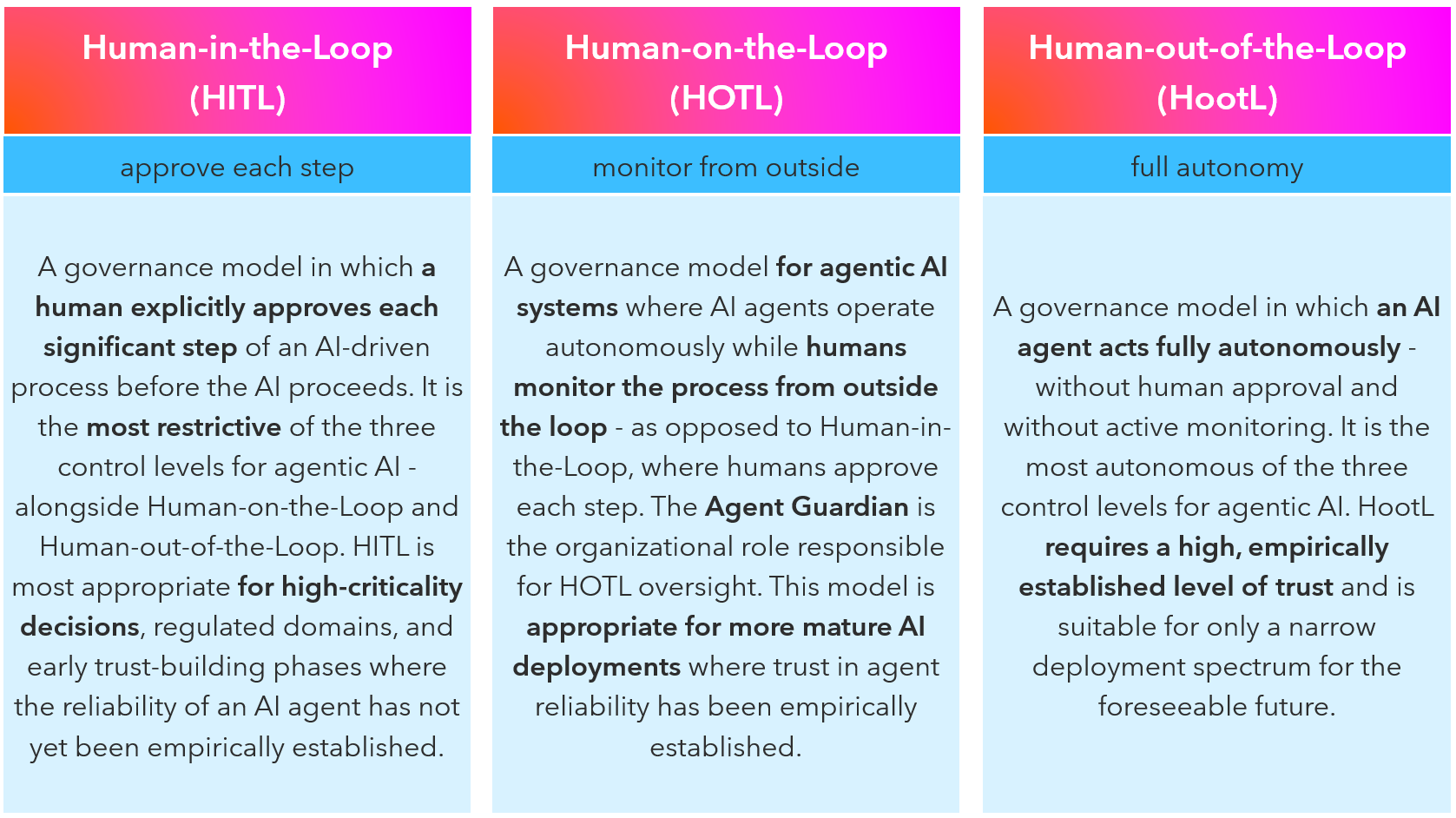
Human-in-the-Loop (HITL) means a trained human reviews and approves each significant AI action before it proceeds. The agent cannot move forward without explicit sign-off. This is the appropriate model for high-criticality decisions, regulated domains, and the early phases of any new agent deployment - regardless of the domain’s risk level.
As Sol Rashidi pointed out HITL can easily become an automation bias.

Human-on-the-Loop (HOTL) means the agent operates autonomously while a human monitors from outside the process. A dedicated Agent Guardian role watches for anomalies, holds escalation authority, and can activate rollback when agents exhibit unexpected behavior. This is appropriate for mature deployments where agent reliability has been empirically established.
Human-out-of-the-Loop (HootL) means full autonomy - no approval, no active monitoring. Gartner’s data is unambiguous on the prospects for this model: unsupervised AI deployment will remain below 10% of all agentic deployments through 2028, primarily because organizations have not yet developed the trust infrastructure it requires.
The distinction matters because most organizations are currently deploying agentic AI into environments designed for HITL while simultaneously expecting HotL outcomes. That mismatch is the source of most of the frustration the field is currently experiencing.
The Regulatory Floor
Before exploring how to move along this spectrum intelligently, it is worth establishing what regulators have already decided. The regulatory dimension is not optional, and it is arriving faster than most enterprise governance programs are prepared for.
The EU AI Act and the NIST AI Risk Management Framework both mandate human oversight at defined points for high-risk AI systems.

Human-in-the-Loop Governance - the structured practice of retaining human decision authority over high-risk agent actions through review, approval, or correction at defined checkpoints - is the compliance baseline, not an organizational preference.
This regulatory floor sets the outer boundary on the right side of the autonomy spectrum for high-risk use cases. You cannot slide past it for certain decisions regardless of how much empirical trust your agents have accumulated. Credit decisioning, patient triage, hiring recommendations, fraud flagging - the regulatory mandate for human oversight in these domains is hardening, not softening.

But the regulatory floor only covers the extreme end. The vast middle ground of medium-criticality decisions - where most organizations’ AI portfolios actually live - is where the real governance design challenge sits.
The Seven Levels Between “Human Decides” and “Agent Decides”
The Human-AI Delegation Framework provides the most practical tool for navigating that middle ground. It maps seven delegation levels across the full spectrum:
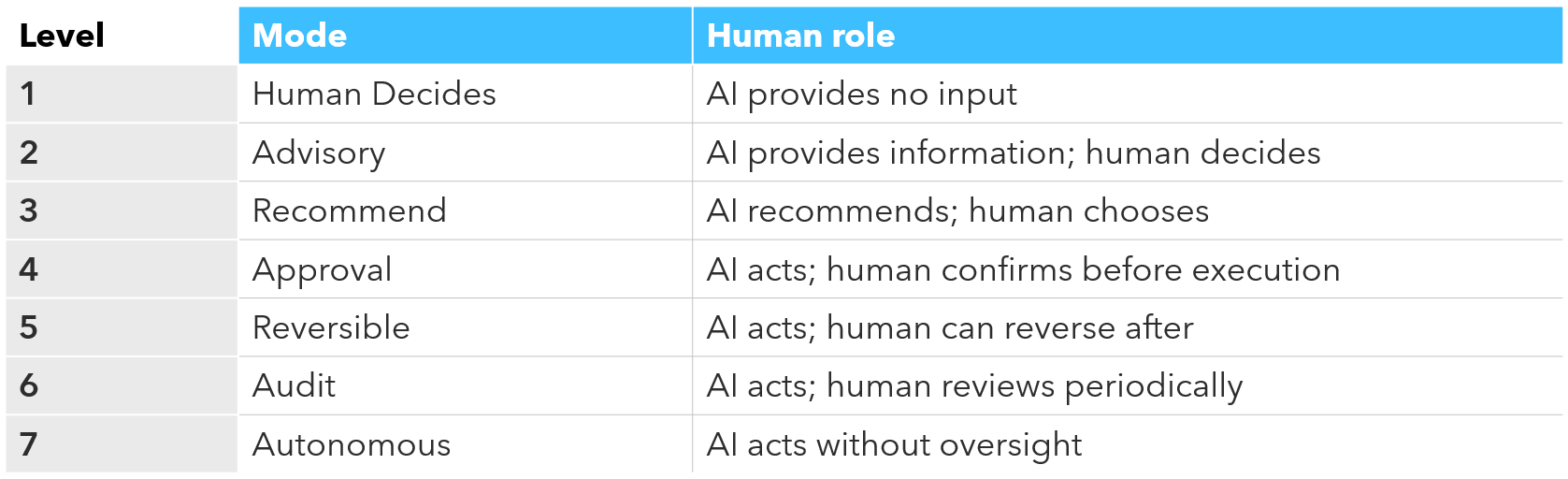
Human-in-the-Loop governance covers levels 1 through 4 — the range where human judgment gates or checks each action. Levels 5 through 7 represent Human-on-the-Loop and Human-out-of-the-Loop territory.
“Organizations prefer Decision Augmentation over Automation by a 2:1 margin.”
- Gartner D&A Summit 2026
That 2:1 preference for levels 2–4 is not irrational. It reflects where organizations currently have the trust foundation to operate. The question is whether it reflects where they want to be in three years - and whether they have a deliberate path to get there.
The framework’s key design principle is that Use-Case Criticality - not organizational preference or technical capability - should determine the appropriate level. Low-criticality decisions can tolerate higher autonomy even with lower trust. High-criticality decisions require tighter human oversight even with high trust. Getting this classification right is the first governance task. Most organizations haven’t done it.
The Infrastructure That Makes HITL Work Without Becoming The Bottleneck
Human-in-the-Loop sounds simple until you try to operate it at scale. When an organization has dozens of agents running thousands of decisions per day, “a human approves each step” rapidly becomes either a fiction or a full-employment program for approvers who scan and rubber-stamp rather than genuinely review.
The Trustworthy-by-Design framework addresses this directly. Rather than treating HITL as a blanket approval requirement, it calls for simplified HITL controls - oversight mechanisms at critical decision points rather than every step, designed to make meaningful human review possible without creating paralysis.
Four design elements make this work:
HITL controls embedded at critical junctures - not as a blanket post-step approval, but at the specific moments where agent errors would have the highest consequence
Transparent interfaces showing agents’ reasoning, confidence levels, and the data they drew on - enabling reviewers to make informed judgments rather than binary thumbs up/down decisions
TTT (Time-to-Trust) metrics - quantitative benchmarks measuring how quickly a new agent or workflow accumulates sufficient trust evidence to support a relaxation of controls
Hybrid AI architectures combining classical AI (deterministic, reliable) with generative AI (flexible, contextual) to reduce hallucination risk and make oversight more tractable
The organizational side of this is equally concrete. Gartner identifies the Agent Guardian as the human role that makes Human-on-the-Loop (and, by extension, the transition from HITL) operationally viable. This is not a new full-time headcount in early deployments - Gartner recommends assigning it as a responsibility to existing senior D&A professionals who combine high AI competency with deep domain knowledge. Their mandate: monitor agent performance against SLAs, define escalation rules, maintain audit trails, and hold rollback authority.
The AI Agent Code of Conduct provides the behavioral framework those guardians enforce - 10 principles covering transparency obligations, autonomy limits, escalation paths, and audit requirements for enterprise AI agents. Only 23% of organizations are currently confident about their GenAI governance. That number suggests most Agent Guardian roles, where they exist at all, are operating without a clear behavioral specification for the agents they oversee.
The Slider, Not The Switch
Here is the conceptual shift that changes how practitioners tend to think about this: Human-in-the-Loop is not a binary setting - it is a position on a continuous dial.
The Autonomy Slider design principle captures this well. Rather than choosing between “humans in the loop” and “agents autonomous,” organizations can position oversight at any point along a continuous spectrum - from fully manual exploration to fully automated execution - and move that position deliberately as conditions change.
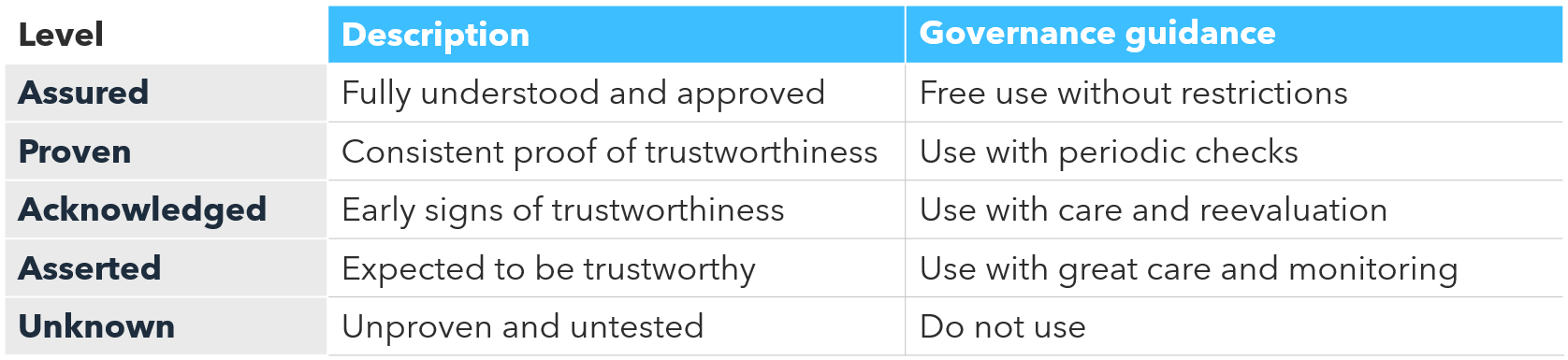
The Graduated Trust Model provides the governance mechanism for moving the slider rightward. It replaces the binary “trusted/untrusted” paradigm with five trust levels - Unknown, Asserted, Acknowledged, Proven, and Assured - and applies them not just to data assets but to AI agents themselves. An agent that has accumulated sufficient performance evidence moves from Acknowledged toward Proven. At Proven, the Graduated Trust Model supports relaxing HITL controls to Human-on-the-Loop monitoring. At Assured, HootL becomes defensible for appropriate use cases.
The practical implication is that every new agent deployment should begin at HITL, with an explicit plan for what evidence would be sufficient to justify moving the slider toward HotL. Organizations that do not define this upfront tend to leave agents at HITL indefinitely - which means the automation never delivers its value, and approval fatigue eventually degrades oversight quality to meaninglessness.
New agent deployed
│
▼
HITL (levels 1–4)
│
Trust evidence accumulates
(TTT metrics, performance data, audit trails)
│
▼
HotL (levels 5–6)
Agent Guardian monitoring
│
Trust level reaches "Proven" or "Assured"
│
▼
HootL (level 7)
For low/medium criticality, non-regulated use cases only
Trust-calibrated path from oversight to autonomy.
What This Means For Data and AI Leaders
HITL is the governance starting position - designing the exit from it is also governance work. Every agent deployment that begins with HITL controls and has no defined trust-accumulation path will stay at HITL indefinitely. That is a governance failure of omission: not a policy violation, but a strategic stall.
Use-Case Criticality classification should happen before agent design, not after. The governance level an agent requires should be determined before the team specifies the architecture. Starting with the criticality classification forces the right conversation early - and often reveals that organizations are applying HITL-level governance to decisions that warrant level 5 or 6.
The Agent Guardian role needs a job description, not just a title. Organizations that are assigning HITL oversight to senior professionals without defining escalation rules, SLA thresholds, audit trail requirements, and rollback protocols are creating the appearance of governance, not its substance. The AI Agent Code of Conduct provides the behavioral specification that makes the role meaningful.
The regulatory floor is rising. EU AI Act requirements for high-risk AI oversight are not a distant eventuality - they apply to systems already in production in regulated domains. Organizations that have not mapped their agent portfolio against criticality classifications and identified which deployments fall under mandatory HITL requirements are accumulating compliance risk alongside their AI deployments.
The Question That Reveals Organizational Readiness
Gartner’s trust research asks the right orienting question: “What would it take for you to trust AI to make decisions that affect your life?” Reframed for the enterprise context: “What would it take for your organization to trust an AI agent to make this decision without a human in the loop?”
That question has an answer - a specific answer, involving evidence thresholds, monitoring requirements, escalation protocols, and use-case criticality assessments. Organizations that can articulate that answer for each agent in their portfolio are building real AI governance. Organizations that cannot are relying on HITL as a substitute for governance rather than as its starting point.
The move from Human-in-the-Loop to Human-on-the-Loop is not a loosening of oversight. It is a maturation of it - from approval-as-safety-net to trust-as-infrastructure. The slider does not move by accident. It moves because someone designed the path, measured the evidence, and made a deliberate governance decision.
Most organizations have not yet made that decision. The ones that do will find that the agents they were waiting on are already ready to run.
This resonates very much with me. The enterprise maturity on this topic is mostly extinct.
Right controls facilitate and accelerate. Tight controls everywhere are more often a bottleneck. Most likely the reason for enterprises not seeing the gains from AI that they anticipate.