

Is Data Mesh 2.0 coming?
According to Zhamak Dehghani's latest updates

Zhamak Dehghani introduced Nextdata OS on 22.04.2025. She named it “The development and operating platform for autonomous data products“. From the first impressions I gathered the following aspects:
❇️ The promise of Nextdata‘s Autonomous Data Products is agility and semantics at scale, adaptability and simplicity
❇️ Multi-cloud and the data solution of your choice for storage, compute, serving, AI and analytics are possible
❇️ Own semantic models within the Data Product makes multiple semantics available for consumption
❇️ Data Products manages upstream dependencies - no central orchestration needed
❇️ Data Products create a semantic graph without a central semantic layer, which makes semantics scalable
❇️ Every Data Product is self-governing
❇️ In a Demo they showed how AI Agents can access enterprise data via MCP for save discovery
❇️ Based on Nexty, the integrated AI you can discover domains and data products in your legacy code base to find starting points for migration and evolve from there
The Q&A
In their latest Q&A session with Joe Reis and others they talk about the following questions:
Topic 1 - Data Products
Question: Can you make us familiar with Data Products to establish a baseline?
Answer: Let’s start with the definition of Data Products, as the term is widely used but often misunderstood. A definition is based on Marty Kagan's product definition (usable, valuable, feasible). Furthermore in the book the"DAV units" (Discoverable, Addressable, Valuable) and the technical capabilities like orchestration, generation, transformation, analysis, access, discovery, and composition are important. Earlier, insufficient incarnations of Data Products as renamed tables or files with metadata or as automation of infrastructure provisioning were available. An autonomous Data Product today is defined as the entire data supply chain in a box applied to a particular business domain, which should manage itself and hide all the complexity of data generation and access.
Source: Zhamak Dehghani - Autonomous Data Products, Data Mesh, and NextData - Q&A
Topic 2 - Product Mindset
Question: What is the change in the "Product Mindset" since writing the Data Mesh book and the difficulties in implementing it in practice?
Answer: The Product Mindset is wonderful and has been embraced by some organizations, but it is impractical if the product doesn't even meet basic quality standards or is inaccessible.Data Product Managers often lack control over data quality, pipelines, or the design of the product because these functions are scattered across different tools and teams. It is almost impossible to have control over the "manufacturing" of the Data Product given the current complexity of data infrastructure. She notes that the title "Data Product Management" exists on LinkedIn, but these roles are often as ineffective as Data Stewards were in the past.
Topic 3 - Purpose of Nextdata OS
Question: Is Nextdata OS meant as a solution for these present problems (see Topic 2)? Does the concept of a "Data Flywheel" (from ingestion to consumption and management) is relevant here and does Nextdata OS encapsulates this for a whole supply chain?
Answer: The concept of the flywheel can be confirmed, but we have to clarifies that it is not about all of the data, but about micro-elements or small/large units focused on a particular area of a business, a domain, or a single semantic. The goal is to enable autonomy, similar to microservices. They should be independent and could be managed by different teams with different stacks but should be able to use each other. Example are Data Products for retail sales, warehouse sales, and multi-channel sales. A Data Product for multi-channel sales would need to encapsulate everything required to be reliably and high-quality generated, accessible, and manageable, which currently requires stitching together many tools.
Topic 4 - Domain Ownership & Gateway Data Products
Question: What are the key learnings since the book's publication, particularly from early adopters, and have these learnings influenced Zhamak’s thinking? What is particularly the challenge of domain ownership and how early adopters are trying to bridge the gap between software and data teams?
Answer: The first principles of the book (first part) likely still hold. Domain ownership (second part of the book on architecture) has been the most difficult. Modern data technologies are often optimized for data engineers and scale poorly for distributing data creation beyond central teams. The democratization of data creation is moving slowly. Many organizations are doing a version of Data Mesh, but it often remains confined to a decentralized data team without truly removing the organizational bottlenecks.
Regarding the gap between software and data (OLTP/OLAP Gateway): Yes, this divide still exists from the technological layer to the human level. Technologically advanced companies ("Digital Scale-ups," "Hello Worlds") are hitting this bridge by trying to build "Gateway Data Products". Most others are still doing Data Mesh "down the pipe" after data has landed in Data Lakes or Warehouses. There is a lack of tooling that makes it easy for software engineers to build data products, even if the technical "ingredients" (like Kafka) are in place. She sees this as the next important frontier to be solved.
Topic 5 - Companies where data is the product
Question: What about companies where data is the product (e.g., financial data companies) and how do their organization compares to the Data Mesh concept for internal enterprise data?
Answer: She was initially hesitant to use the term "product" to avoid people immediately thinking of commercial transactions. She sees the connection in that even in these companies, processes and people are responsible for generating the data and need to be empowered to build something over whose quality they have control. The control of the supply chain to be able to sell the product with confidence is covered by the Data Mesh concept. The layer of the commercial transaction itself was not a primary part of the Data Mesh ingredients but can be built on top. Such companies often have product-oriented verticals for data products and mechanisms for discovery and access, both internally and for external customers. The difference might lie in the very real, legal character of contracts compared to "softer" data contracts internally.
Topic 6 - Functional description of Nextdata OS
Question: Asks for a functional description of the Nextdata OS platform, particularly regarding the different levels of data modeling and the "Drivers" that control different parts of the stack?
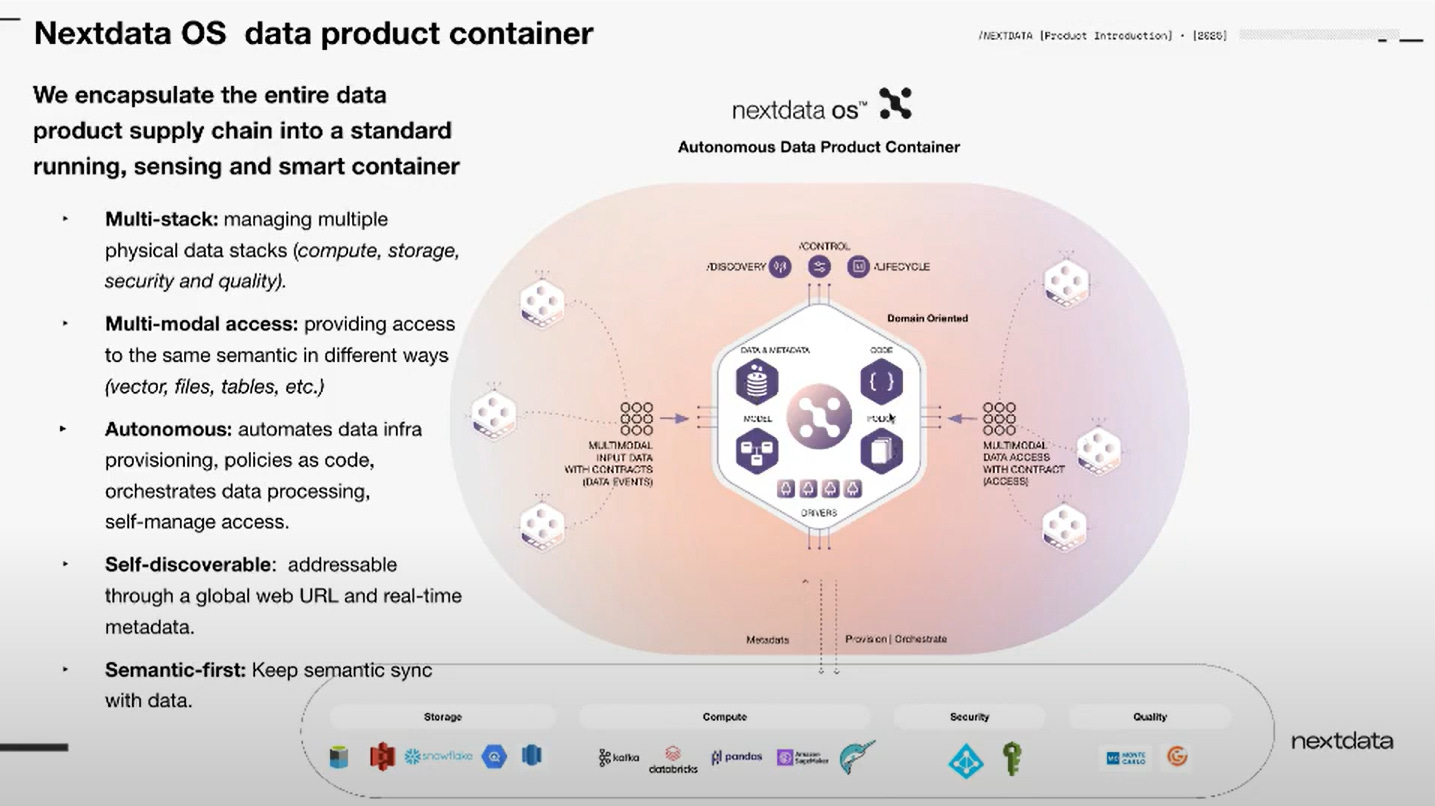
Answer: Nextdata OS is a technology that allows the concept of autonomous data products to be codified. They have built a runtime and build-time environment (similar to containerization for applications) that allows independently managed data "applications" (autonomous data products) to be created, run, and accessed. The platform provides an abstraction that allows users with basic data processing and modeling experience to declaratively describe their data product:
Data Model/Semantics: Describing fields, values, types, relationships, and rules.
Code: Writing the logic to generate, transform, and analyze the data in the preferred language.
Dependencies: Defining dependencies on upstream datasets (inputs).
Contracts & Controls: Defining rules to govern and validate the data.
Orchestration/Compute: Defining how and when the code should run (e.g., based on changes in inputs). and where (on which compute engine like Spark, Snowflake, R).
Outputs: Defining the promised data models, freshness, and access modes (e.g., Lake Storage, Snowflake). The platform validates that these promises are met before data is made accessible.
The platform automates the provisioning of infrastructure for storage, compute, access control, and quality measurement. It orchestrates the execution of the code by sensing changes in inputs. The data products behave like running applications providing APIs to get information and access to the underlying data. The simplicity of the declaration abstracts away the complexity of the underlying technologies. The goal was to build this so it doesn't become another central monolith platform; each unit (Kernel and Drivers) should function independently and potentially be Open Source to enable decentralization.

Source: Zhamak Dehghani - Autonomous Data Products, Data Mesh, and NextData - Q&A
Topic 7 - Open World Assumption
Question: Is the Next Data OS platform is based on an Open or Closed World Assumption? For example whether an external source like Harvard Dataverse could publish a dataset as a data product using the ADP specs that could then be consumed by anyone, or if it would first need to be internally imported and republished.
Answer: We have made Open World Assumptions. At the level of the data product itself, there is an API to access its information (metadata). The data product APIs also give access to the underlying storage location, wherever that may be. However, the data itself is currently not yet flowing through the data product APIs; the API points to the storage location. This means that access to the data itself still depends on the accessibility assumptions of the underlying storage platforms, very few of which make Open World Assumptions. The distinction between metadata/information and the data itself is important here. Flowing the data through the container would introduce complexity regarding performance and throughput, which they chose not to solve currently.
Topic 8 - Usage of dbt (data build tool)
Question: What are the thoughts on dbt (data build tool), specifically the use of dbt Mesh for Data Mesh architectures (with its limitations) and the possibility of dbt drivers for connecting Nextdata OS to Data Products created via dbt pipelines.
Answer: Describes dbt primarily as a compute engine often sitting on Snowflake and facilitating SQL workloads. From the perspective of Nextdata OS, which is a layer above, dbt is essentially a compute option or a driver. Nextdata OS is agnostic regarding the compute technology and abstracts it away; there are drivers for different computes (Spark, Snowflake, R) and storage (Lake Storage, Snowflake).
Regarding using dbt for Data Mesh capabilities: She has not used dbt Mesh "in anger" and cannot give a strong opinion. However, she looks at the origin of technologies to understand their boundaries. dbt is primarily a build tool for SQL workloads with a great developer experience. The boundaries are that it is geared more towards that kind of workload than "any platform anywhere". A SaaS model like dbt Cloud is great for smaller companies that don't want to run their own infrastructure, but if you truly believe in a mesh that connects any data anywhere, then a SaaS provider limited to one platform is potentially a constraint.
Main Concepts discussed
Data Mesh
A decentralized approach to data management that shifts ownership and accountability for data to the business domains where it originates or is used. It moves away from centralized data teams, pipelines, and monolithic platforms.
Born out of frustration with slow, brittle, costly, and untrusted centralized data management.
Promises scale, speed, self-service end-to-end data usage, and automated governance.
Requires fundamental changes to the operating model across technology, processes, organization structure, and principles.
Shifts from data as a movable asset to data as a fully functioning, autonomous product.
Aims to create a unified, decentralized, and automated solution.
Faces challenges in adoption due to legacy processes, technology, and culture.
Ideal implementation creates closed loops between operational and analytical systems.
Frequently misinterpreted or partially implemented, leading to "antipatterns".
Data Products / Autonomous Data Products
The fundamental building blocks of the data mesh, envisioned as domain-oriented, decentralized units. An autonomous data product (ADP) is a more complete encapsulation of the entire data supply chain for a domain concept.
Encapsulates data, code, control, and semantics.
Automatically discoverable and uniquely addressable.
Self-governed with policies as code, always up-to-date and trusted.
Streamlines data processing and access.
Tames complexity and amplifies autonomy.
Defined by declarations (e.g., Python, YAML, SQL), specifying inputs, outputs, contracts, and controls.
Self-orchestrates based on upstream dependencies.
Defines its own semantic models, contributing to a living semantic graph.
Multimodal: Can serve the same semantic data in multiple shapes and formats for different users (analysts, scientists) and AI agents.
Accessible via a single web addressable URL.
Purpose-built for the AI era, providing needed trust, discovery, and usability for agents.
The concept was refined to mean the "entire data supply chain in a box applied to a particular business domain".
Requires a product mindset (focus on usability, value, feasibility) but this is challenging when the underlying manufacturing (data generation, quality) isn't easily controllable with traditional tools.
Distinct from simply renaming data tables or files as data products with metadata.
Nextdata OS
The autonomous data platform introduced by Nextdata that aims to make Data Mesh at scale a reality. It provides the necessary technology for building and managing autonomous data products.
Offers tools for different roles: Creators build ADPs, Consumers discover/access data, Platform Engineers integrate stacks, Platform Owners observe health/insights.
Uses a modular runtime kernel and an extensible, dynamic driver architecture to integrate with existing data stacks (compute, storage, security, quality).
Provides a unified and simple experience despite underlying stack diversity.
Enables computational federated governance by providing the capability to embed, execute, and monitor policies as code locally within ADPs.
Supports centrally validated global policies that are executed locally.
Provides visibility into mesh performance and policy violations.
Designed to contain failures locally within ADPs.
Offers containerization technology to encapsulate complexity of legacy data/pipelines.
Includes Nexi, a multi-agent AI assistant to analyze legacy code/data and bootstrap a mesh of ADPs.
Built as an open platform with accessible APIs for integration and extension.
Plans to open up driver SDKs and potentially the kernel itself in the future.
Seen as an abstraction that simplifies the technical aspects of defining and managing data products.
Computational Federated Governance
An operational model for data mesh that moves governance from centralized, manual processes to automated, policy-as-code execution embedded within autonomous data products.
Essential for automating compliance and governance at scale, especially with increasing data velocity and AI consumption.
Addresses complex requirements, such as those in drug discovery, where governance involves not just access but purpose of use.
Policy as code is continuously executed and validated in the lifecycle and upon data access.
Balances local autonomy and control within domains with global compliance requirements.
Enabled by the kernel running inside each data product.
Global policies are centrally defined and validated but executed and enforced locally by the ADPs.
Promises (guarantees made to consumers) and Expectations (requirements from upstream sources) are defined and enforced locally.
Provides visibility and mechanisms for remediation of policy violations.
Complexity (Data Complexity)
The inherent and rapidly growing difficulty in managing data due to its diversity, distribution, volume, evolving usage, and interaction with AI/ML.
Data exists everywhere in many shapes and formats, is processed countless ways, and used by a wide range of applications and people.
AI agents and LLMs add more use cases and exponentially increase complexity (combinatorial problem).
Traditional monolithic or fragmented approaches fail to manage this.
Needs a technology that embraces complexity by encapsulating fragments.
Encapsulating complexity with new abstractions (ADPs, Data Mesh OS) is the key to transformation.
Seen as a bottleneck stopping innovation.
Data Mesh Antipatterns
Common ways organizations partially or incorrectly implement data mesh principles, limiting its transformative power. These antipatterns miss out on the benefits of true decentralization. They Result from adopting small steps without relentless consistency towards the full vision. Often limited by existing ways of doing data.
Partial Data Mesh: Reducing data products to simple, static datasets with metadata; minimal domain involvement; absence of computational governance. Leads to "dumb" data products.
Open Loop Data Mesh: Static data products served from downstream storage (lake/warehouse), lacking domain-centric collaboration and the closed-loop connection to operational systems. Often due to pipeline hairballs and lack of domain tools.
Proxy Data Mesh: Centralized data teams or siloed domain teams acting as proxies, reverting to pre-mesh problems of silos and bottlenecks.
Nexi
Next Data's multi-agent AI assistant designed to help with the challenges of adopting Data Mesh, particularly in dealing with legacy systems.
A helpful AI friend for working with Next Data OS.
Analyzes legacy code (like SQL scripts, ETL jobs) and data.
Designs and builds domain-oriented data products.
Can bootstrap a mesh of connected autonomous data products from zero, grounded in existing code and data.
Removes guesswork and provides a fast starting point for transformation projects.
Functions as a multi-agent system (e.g., mesh architect, data product modeling agent, data product coding/implementation agent).
Rearranges legacy code into clean ADPs, adds quality checks, defines contracts, and writes declarations.
Helps bridge the gap between technical names and business language for semantic models.
What is your impression about Nextdata OS? Is it the next step in the evolution of Data Mesh solving current challenges?
Peter, as far as I am concerned this is Data Mesh 1.0.
If we want to get pedantic many things in Nextdata OS were called out in Zhamak's 2022 book, so she has just spent 3 years building it. Aside from some implementation details, like the poly-compute concept, and the use of Gen AI in Nexty most of this is in the book.
In my view all the intermediate steps and products (like dbt mesh or Data Mesh Manager) are 0.x version of data mesh. In the sense that they did not fully address the complete data mesh set of principles. Most specifically they did not allow for autonomous data products.
Now I am not critical of these initiatives. After all dbt mesh needs to fit into the existing dbt eco-system and address migration concerns for existing customers. None of these intermediate, what I call 0.x products, had the resources, the dedication and the vision of Nextdata OS. Not to mention the ability to start from a different place.