
Shifting Left - Evolution of Data Quality and Consumer Satisfaction
The New Paradigm for Data Quality and Governance in the AI Era

Shift Left is addressing important topics to bring our understanding and maturity of Data, Analytics and AI to the next level. After starting already with an article from my colleague Johannes Wenzel about “Shift Left in Data & Analytics” I want to give another perspective in the following article.
Based on posts, podcasts and articles from Chad Sanderson, I dived into “Shift Left” and the meaning for Data Quality.
In today's data-driven world, data has evolved from a mere byproduct to the very essence of business operations, fueling strategic decisions, unlocking innovative AI models, and becoming a foundational asset. However, this power comes with immense responsibility. Organizations globally grapple with persistent data quality and governance challenges, jeopardizing trust and hindering the true potential of their data initiatives.
The Pervasive Problem of Poor Data Quality and Reactive Governance
Many enterprises struggle with data that is untrustworthy, inconsistent, incomplete, or inaccurate. This leads to a myriad of problems: incorrect analyses, model failures, and the classic "Garbage In, Garbage Out" scenario, particularly detrimental for AI applications. The lack of trust is palpable, with a significant discrepancy between C-suite executives and individual contributors regarding the accuracy of financial data.
This pervasive issue stems from several root causes:
• Accumulation of Data Debt: Unmanaged changes, lack of version control, and suboptimal reactions to data changes lead to complex, opaque "spaghetti data architectures".
• Reactive Approaches: Traditional data management tools and governance frameworks often identify problems after they have occurred, making resolution costly and time-consuming. This is exemplified by the "1:10:100" rule, where fixing an issue in production can be 100 times more expensive than addressing it during design.
• Siloed Workflows and Lack of Ownership: Data producers, typically software engineers, are often unaware of how their data is used downstream, making it impossible for them to manage changes effectively or take responsibility for data quality. This communication breakdown is a direct manifestation of Conway's Law, where organizational communication structures are mirrored in system architectures.
The Critical Role of AI in Data Quality Management
The advent of Artificial Intelligence (AI) serves as a major catalyst, intensifying both the challenges and the urgency for robust data quality and governance. High-quality, trustworthy, and contextually rich data is paramount for the success of AI and Machine Learning (ML) models. Without it, AI systems risk hallucinating or providing unreliable insights, making it difficult to discern if model errors are due to incorrect data or the model itself.
However, AI can also be a powerful ally in enhancing data quality:
Automated Profiling and Cleansing: AI-powered data quality tools can automatically scan and profile source data, identifying anomalies, inconsistencies, and duplicates that human eyes might miss, especially during data migrations.
Contextual Understanding and Code Analysis: AI can help analyze code and interpret context, making it "10 times easier to shift left" by inferring the meaning of data from the code that produces it. This can bridge the gap between deterministic data flow (what data goes where) and the human-like contextual understanding required for effective data management.
Enhanced Data Access: AI-powered chat interfaces are becoming the new standard for enterprise data access, enabling users to discover hidden data and insights by layering chat capabilities on a richly curated metadata foundation.
"Shift Left" Data: A New Era for Data Management
According to Chad Sanderson, the solution to these deeply entrenched problems lies in a fundamental paradigm shift: "Shift Left" Data. Originating from security (DevSecOps) and operations (DevOps), where proactive measures proved indispensable, "Shift Left" means embedding data quality, governance, and compliance practices as early as possible in the software development lifecycle, ideally directly into the code that produces the data.
This approach transforms data management from a reactive firefighting exercise into a proactive, preventative discipline. It acknowledges that data is code, or more accurately, produced by code, and therefore, managing it well means starting at its point of creation.
I wrapped up my understanding in the following overview:

Fig. 1: Shift Left - Overview
A comprehensive "Shift Left" framework encompasses three categories of quality checks:
Design-Time Quality: Focuses on the code that produces data. By integrating data quality best practices, unit testing, and integration tests into the software development lifecycle, defects can be caught at the earliest, most inexpensive stage. This fosters collaboration between engineers and data teams to define how data should be produced and communicate changes before they materialize.
Run-Time Quality: Evaluates data as it is produced at runtime, before it's pushed downstream. This provides the shortest feedback loop for upstream teams to diagnose and treat problems at the source, significantly shortening root cause analysis.
Consumption-Time Quality: The traditional approach, involving anomaly detection and trend analysis on aggregated data in analytical databases. While useful for catching unexpected errors, it is reactive and the most costly to mitigate.
The ideal framework prioritizes Design-Time checks, allocates moderate resources to Run-Time checks, and reserves Consumption-Time checks for the long tail of unforeseen issues.
Data Contracts: The Cornerstone of "Shift Left"
Central to the "Shift Left" movement are Data Contracts. These are formal, programmatically enforceable agreements between data producers and data consumers.

Fig. 3: How a Data Contract works
They serve to define expectations regarding:
• Schema: Column names, data types, and required fields.
• Semantics: The business meaning and context of the data. This addresses the critical issue of semantic ambiguity that often plagues AI systems.
• Service Level Agreements (SLAs): Such as data refresh frequency and quality thresholds.
• Other Governance Rules: Including PII rules, compliance standards, and ownership details.
The primary goal of a data contract is to establish clear ownership. Without explicit ownership, contracts have little utility.
Enforcement is critical; a contract without enforcement is merely documentation. Enforcement should ideally happen programmatically within CI/CD pipelines. This allows for the prevention of backward-incompatible changes before they are deployed to production, providing immediate feedback to data producers. For instance, a change to a timestamp format from local time to UTC could be flagged by a data contract before deployment, alerting affected downstream ML models and data scientists.
Data contracts can be categorized into two main types:
• Data Code Agreements (DCA): Focus on the code that generates or alters data at "egress points" (where data leaves one system to flow into another). DCAs are crucial because software engineers are willing to own code, not abstract data artifacts. By framing data ownership in the context of code, adoption becomes significantly easier for developers.
• Data Product Agreements (DPA): These are more aligned with traditional data quality rules that data engineers and analysts typically expect, such as latency requirements and event ordering.
Furthermore, version control for data contracts is as crucial as it is for APIs, allowing changes to be managed over time and preventing compatibility issues for consumers.
Organizational Shifts: Roles, Communication, and Culture
Implementing "Shift Left" and data contracts necessitates significant organizational and cultural changes:
1. Software Engineers as Data Producers: Software engineers are at the "First Mile" of the data supply chain, responsible for creating data via application code, APIs, or databases. The common misconception that "software engineers don't care about data" ignores the fact that they are already heavily taxed by data-related problems (migrations, outages, understanding data meaning). To gain their buy-in, data teams must frame data management as a solution to their pain points, such as reducing migration nightmares, speeding up root cause analysis for outages, and providing better change management for their outputs. Software engineers primarily think in code and dependency graphs, not traditional data lineage graphs, so the language and tools must align with their existing workflows.
2. Communication and Collaboration: The lack of communication between data producers (software engineers), platform teams, and data consumers is a root cause of many data problems. Data contracts act as a mechanism of communication, ensuring that when changes occur, the right people are informed about potential impacts, fostering collaboration and shared understanding. Techniques like storytelling and asking good questions are vital for bridging communication gaps across disciplines.
3. Cultural Transformation: While technology can facilitate change, data quality is fundamentally a cultural problem. The "Shift Left" approach aims to embed data management best practices so deeply into the engineering workflow that it becomes an inherent part of the culture, similar to how QA and DevOps evolved. By making it easier for engineers to "do the right thing" and demonstrating clear value for their own work, a culture of accountability and trust emerges organically.
Broader Governance and Data Management Components
Effective data governance extends beyond contracts and cultural shifts, incorporating other critical components:
Metadata Management: Metadata is the "infrastructure" for data access and understanding. Modern data catalogs, augmented with AI, should transcend being mere inventories to become conversational interfaces, providing rich context for data assets. Crucially, traditional catalogs often fail because they lack the context derived from the code that produces the data, which is the true source of truth for ownership, business logic, and change history.
Data Lineage: While traditional data lineage maps data flow between databases, it often falls short in complex, multi-technology pipelines involving code and events. A more holistic approach, such as "predictive data lineage," combines data, code, and API information to probabilistically complete the end-to-end chain. For software engineers, lineage is most valuable when framed as dependency graphs, helping them understand downstream impacts of their changes.
Data Product Mindset: Treating data as a product, complete with clear ownership, versioning, documentation, SLAs, and a focus on generating direct ROI, is essential for data engineering to take center stage and for executives to recognize data as a critical business asset.
Unstructured Data Governance: With the rise of Generative AI, the governance of unstructured data (e.g., documents, images, model outputs) presents new, more complex challenges than structured data. New frameworks are needed, encompassing unified metadata pipelines, consistent core policies (access, audit, privacy), and evolving automated lineage and classification tools.
Shift Right and Considering an Holistic View
While shiftig left is very important to create value from data, it is possibly not the only shift which should be considered. Shift Right means addressing the data consumer and getting feedback fast. Not everything can be seen or handled early and we have to guarantee, that consumption-time quality still is observed. While often data teams are already focus on this area, let’s just consider what it can mean and how it can help to see it holistically. The following overview shows different concepts and how to shift them left and right:
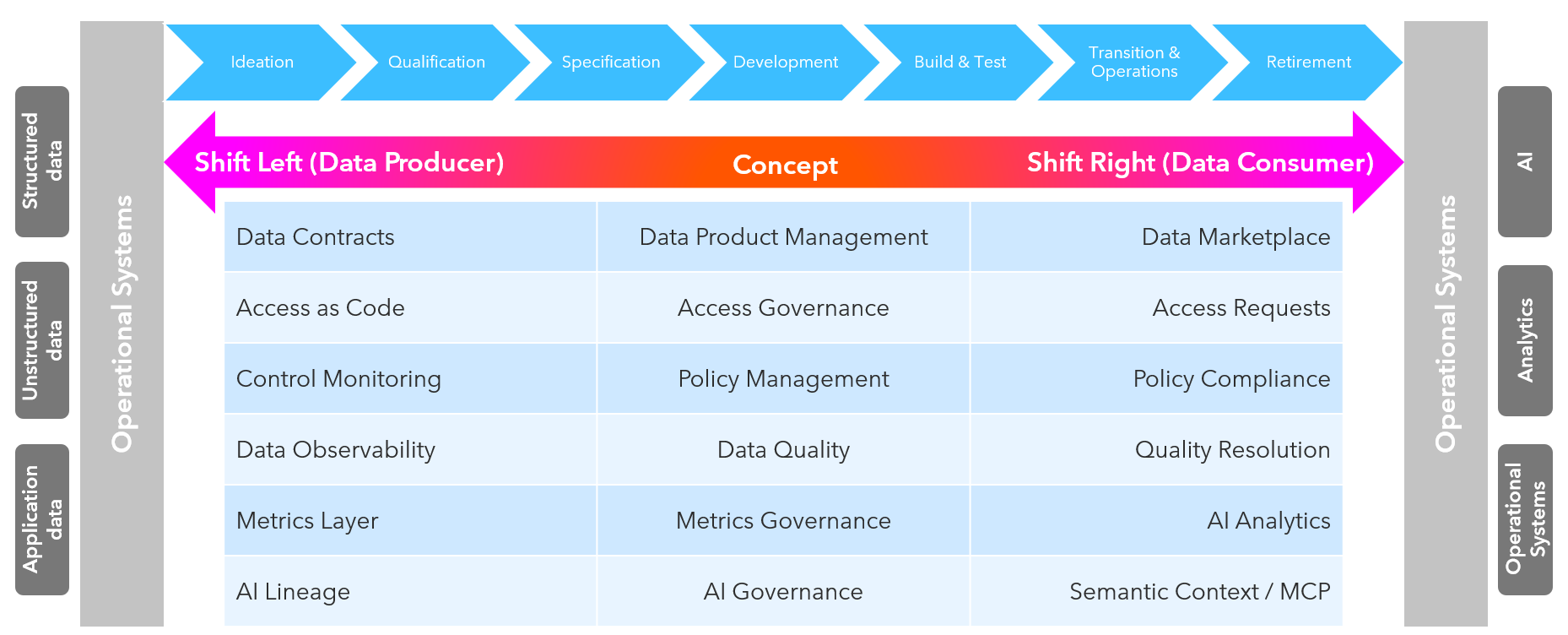
Fig. 3: Shift Left & Shift Right - towards an holistic end-to-end perspective
Starting early is important but a lot of things happen on the other side. Shift Right considers feedback as a core principle.

Fig. 4: Shift Right für responsibility and feedback
In conclusion, the demands of the AI era necessitate a fundamental rethinking of data management. By adopting a "Shift Left" approach, leveraging programmatic data contracts, aligning incentives for all stakeholders, and fostering a culture of proactive data ownership and communication, organizations can transform their data into a reliable, trusted, and valuable asset, enabling them to harness the full power of AI and drive strategic business value.
What do you think about Shift Left and Shift Right, too? What approach for data quality and consumer satisfaction works best for you?
Great article. Thank you. Shift-left is a necessity to keep data governance at pace with scalability.
Without trying to minimize the benefits, it is again about balance. The AI development has shown for years (even before ChatGPT) that explainability and interpretability are more and more important. Now in AI systems that has already become a reactive work, that is trying to include explainability mechanisms after the fact (with great work also to get ahead). In data governance we risk the same, by thinking we can do governance in stealth mode, and still provide trustworthy outcome. The more we do my design, the more we need to communicate on what we are doing to keep trust levels up.
Wow, the part about 'Garbage In, Garbage Out' really stood out to me. It's so true, espacially for AI. This totally builds on the Shift Left discussion from before!