
Snowflake Data Cloud in a SAP Ecosystem for Data & Analytics
Thinking in options and synergies

As I understand it, modern cloud data platforms have developed from two directions. From the one side, solutions like Google BigQuery and Databricks Data Lakehouse Platform started cloud native making best use of capabilites in the cloud. Other solutions like Azure Synapse Analytics, Amazon Redshift or SAP Datasphere, based on SAP HANA Cloud, have there orgin in the classical on-premises realm and adapt to cloud native possibilities over time. Snowflake is a little bit different here, as it was completely new designed for the cloud but came somehow from classical Data Warehouse (DWH) thinking.

Fig. 1: Orientation of Cloud Data Platforms
Snowflake Data Cloud is currently one of the hottest solutions within the Modern Data Stack and represents mainly what MDS means today.
What makes Snowflake such a strong solution?
Snowflake has a very strong market position and is very popular these days. From people coming from classical DWH I hear sometimes disappointment as they expected something magic. But maybe the magic of the Data Cloud is under the hood.
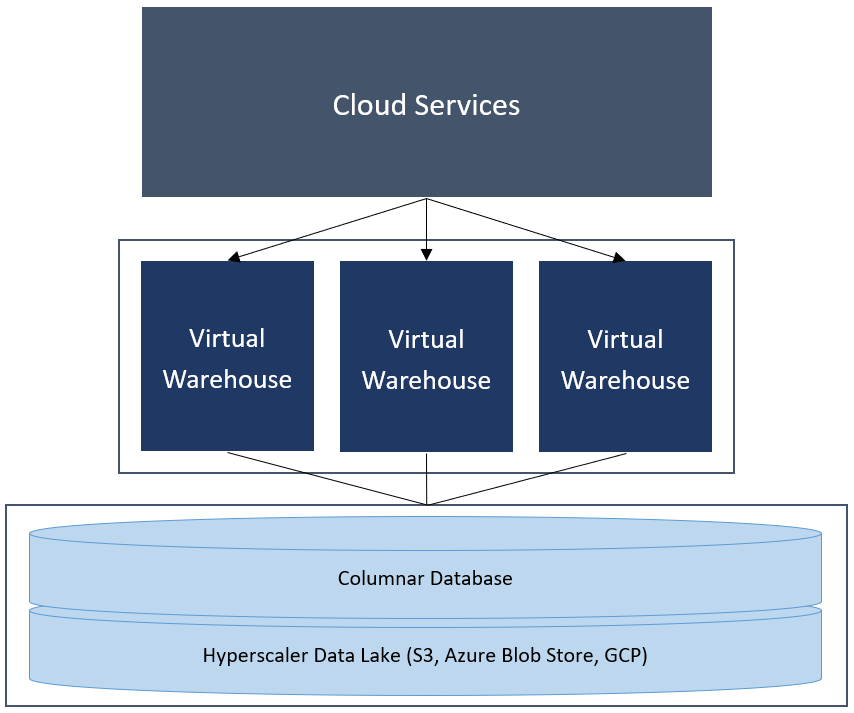
Fig. 2: Snowflake architecture1
Based on a shared-disk approach you got the flexibility through separation of compute and storage, you would expect from modern Cloud Data Warehouses. Additionally the compute represented by the Virtual Warehouses are massively parallel processing (MPP) compute engines with a shared-nothing approach. Snowflake calls this also EPP - Elastic Parallel Processing.
There are some further interesting aspects about Snowflake Data Cloud, I want to mention:
Every Virtual Warehouse consists of CPU, SSD and memory (RAM), can have different node sizes and accesses the same data pool
It runs on all the Hyperscaler - Microsoft Azure, Google Cloud Platform (GCP) and Amazon Web Services (AWS)
There is support of structured and semi-structured data (JSON, ARVO, Parquet, …) what brings in high flexibility
Automatic Compute Scale-out (serverless)
Staging via Data Lake, load data into a proprietary columnar-format and supports now since some time Apache Iceberg table formats
External tables on hyperscaler object storage is possible
Snowflake and SAP Data & Analytics
In my former blog I described in general the aspects of why solutions of MDS and Best-of-Suite vendors like SAP can come together into a data ecosystem for deliver on the value of data.
While Snowflake isn’t a official partner with SAP, I see many customers having both solutions in the house and come to the point where they want them to work together. The following picture shows examples of approaches and possibilites discussed in a customer context.
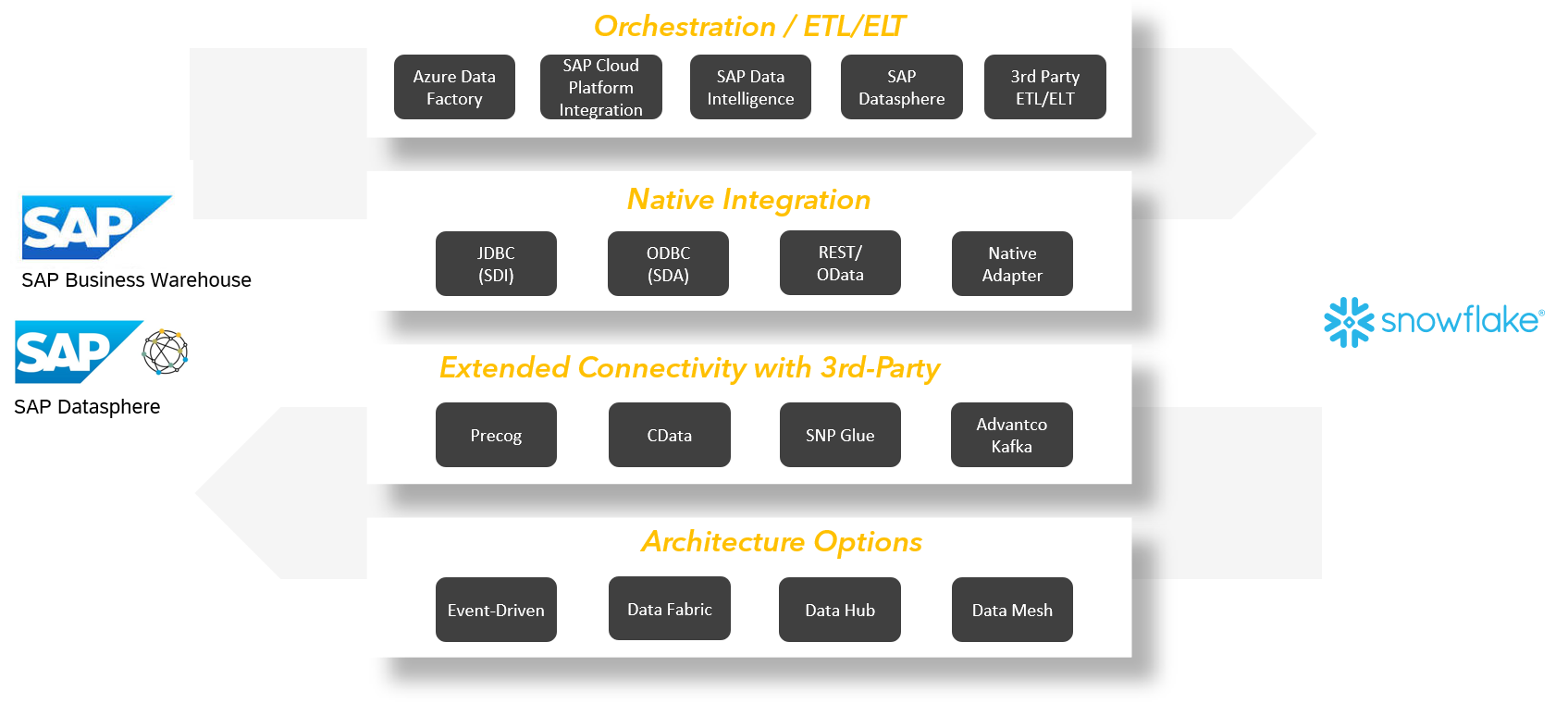
Fig. 3: Approaches for bi-directional communication between Snowflake and SAP data solutions like SAP BW/4HANA or SAP Datasphere
Initially we can see differnt approaches I briefly want to explain:
Orchestration / ETL/ELT - Classical ETL/ELT tools do exactly what they are built for and connect different databases to transfer data between them. There are many possibilities with SAP and non-SAP solutions available which can do the job.
Native Integration - Possibly the first option many think about and for sure open standards supports some options like JDBC which are possible from both sides but also have there downsides.
Extended Connectivity with 3rd-Party - To mitigate the downsides on direct integration with techiques like JDBC some specialists offer advanced integration building on navtive integration or via other components like Apache Kafka/Confluent.
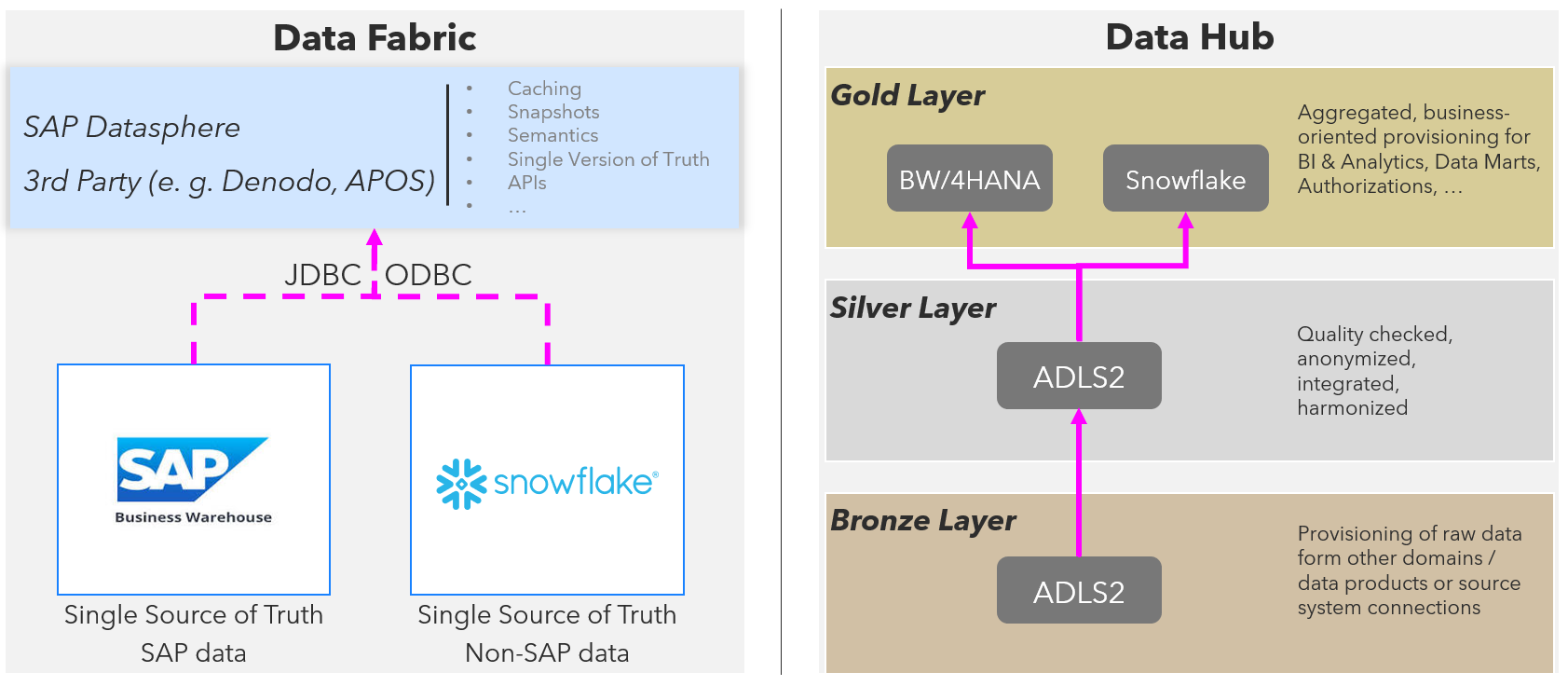
Architecture Options - For sure different architectures also need ways to connect and integrate. But they also bring in another perspective to think bigger about integration. Here is a very simplified sketch of two of these possible options:
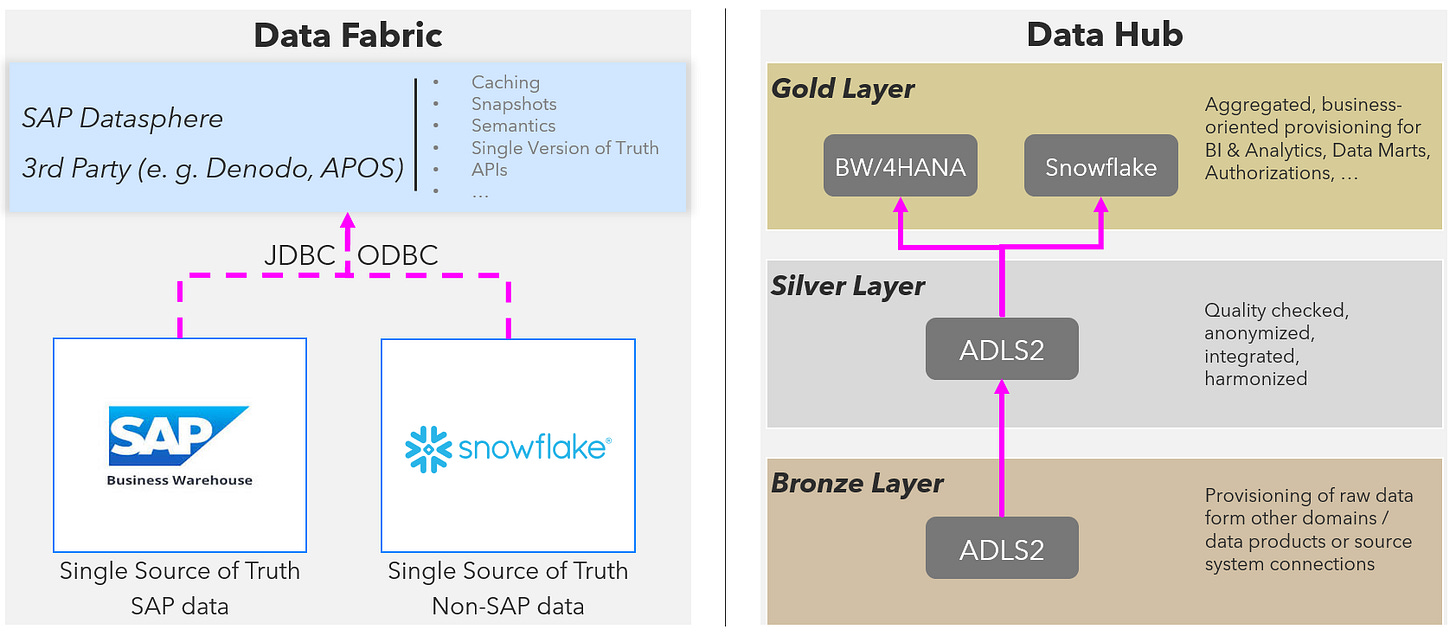
Fig. 4: Architecture options for creating a single source of truth on different technologies
A Practical Use Case
To come down to reality, I will show a use case based on a practical example we described in our whitepaper about SAP & Modern Data Stack2. We called the scenario “eCommerce Optimization for Retail”, as we observed several similar situations on customer side. The Use Case can be described as follows:
Data from different sources is analyzed in a consolidated manner and provided for corresponding services, in order to optimize web shops and display customer specific ads
Data in Snowflake is virtually linked through Federated Query to sales figures from SAP S/4HANA in SAP Datasphere and analyzed with the help of a common business semantic in order to measure success and steer activities
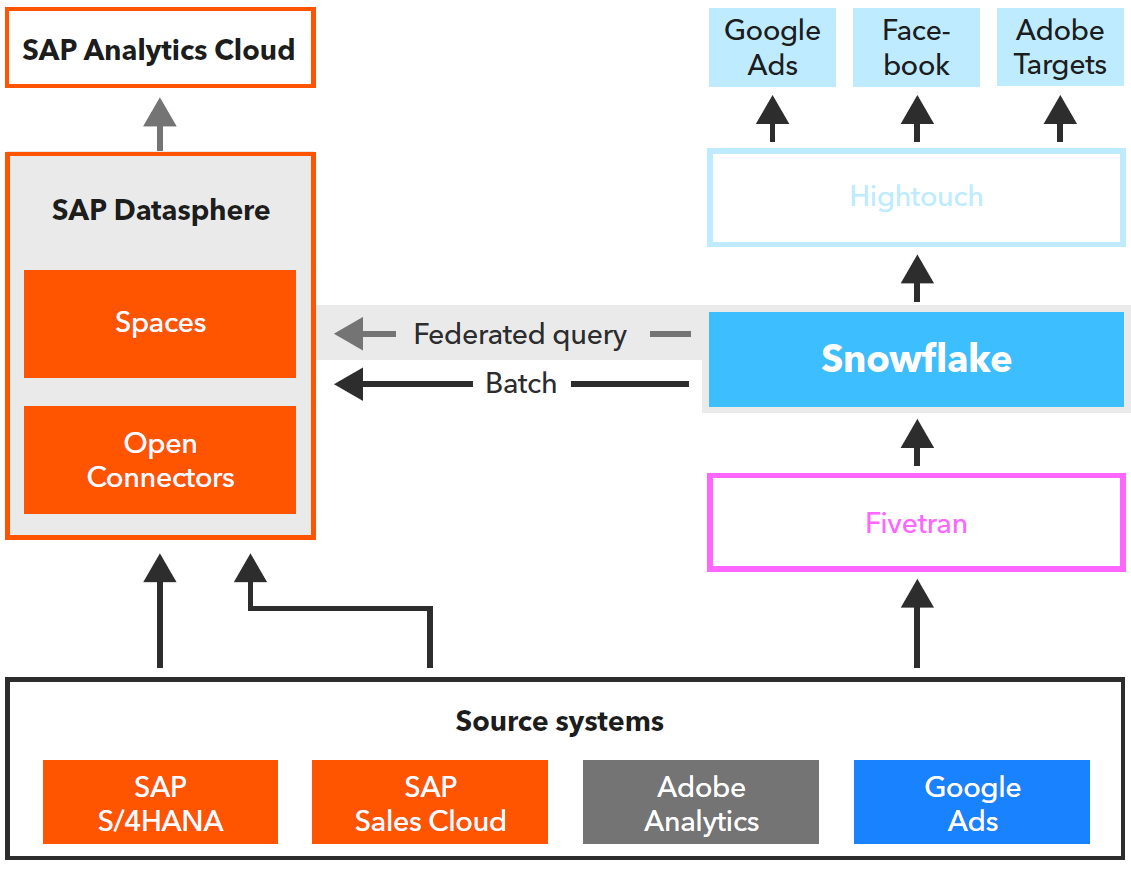
Fig. 5: Integrating SAP Data & Analytics with the Modern Data Stack based on Snowflake
Benefits of this scenario can be seen as follows:
Snowflake Data Cloud proves to be the right solution for integration into the web and cloud environment, and supports marketing and sales through the Snowflake ecosystem integration options via Fivetran (inbound) and Hightouch as Reverse ETL solution (outbound)
Department-specific tasks can be supported through a low code approach of SAP Datasphere, and usage of domain knowledge can be improved via SAP Datasphere Spaces concept to integrate and manage both datasets
Integrating both approaches ensures an integrated and comprehensive view of data from the source systems to manage and optimize activities
We see here that both platforms work together but leverage optimized integration of their specific ecosystems. There may be other solutions and ways to bring these data together as shown above and also the integration of the marketing context could be done by other tools like Customer Data Platforms like this from SAP or others.
This is possibly only on solution and decisions for a long term architecture should be based on a larger context. But the goal of this article was to raise awareness about possible data ecosystems in todays complex data world.
What is your experience with data ecosystems and the integration of SAP D&A and Snowflake Data Cloud? Which experiences do you make and which other ways are you possibly using?
https://docs.snowflake.com/en/user-guide/intro-key-concepts
https://www.infomotion.de/whitepaper-sap-modern-data-stack