

The Modern Data Stack

Much is already written about The Modern Data Stack. Is it just the future of data architecture? Is it the next big thing? Or is it just a marketing hype?
This blog serves as a main blog to start discovering the different aspects of The Modern Data Stack (MDS).
In general my experience is the MDS is characterised by consisting out of cloud-native, plug and play, easy to use solutions with a simple pricing model and a active community. A lot of solutions are just some years old which brings a high innovation to the stack and the technological base is typically one of the hyperscalers where components of the hyperscales can extend the MDS.
Typically a cloud data platform build with components of hyperscaler PaaS- and SaaS-solutions is not what is meant as MDS as this would be a kind of vendor lock-in, not open and flexible enough to optimize for the business purpose. Therefore we can also see a very fast adoption of new concepts and developments, driven by a fast cloud momentum.
We can see an agile fail fast mindset connected with the MDS, optimising the Best-of-Breed approach.
We can see a kind of data architecture buld with the different components of der MDS. Examples of vendors and solutions can be seen as an example as there are typically much more vendors and a fast evolution in the market:
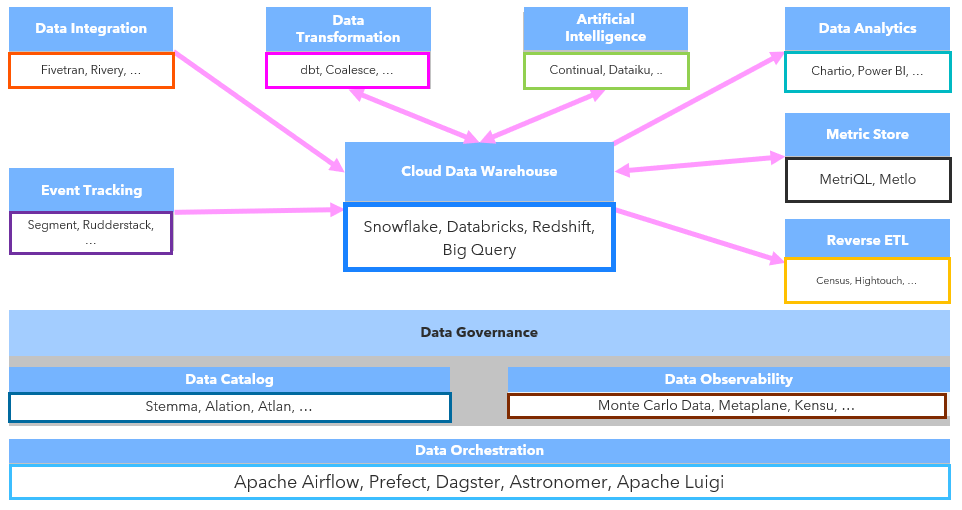
So this is what I recognized about the MDS. I can see the following aspects I want to dig deeper in the next time:
Event Tracking
Data Observability
Data Orchestration
Data Lakehouse
Analytics Engineer (Role)
DataOps
One Big Table / Wide Denormalized Table
Activation of Metadata
Data Contracts
Data Apps
Maybe some special topics like
- Modern Data Stack 2.0
- NGODS - Next Generation Open Source Data Stack
- On-Premise Modern Data Stack (like with DuckDB?)
Maybe there is more to come. Let’s start with it step-by-step.