
Data Catalog for Data Mesh
Enabling Domain Data Teams

The concept of the Data Mesh defines a decentralized data management concept based on modern data platforms and domain-oriented responsibility for the data. This is intended to avoid the bottleneck of a central data management team and improve data quality through proximity to the data producers.
The strong interest in the Data Mesh approach in recent years has also placed the data catalog at the center of this data architecture pattern as a solution component for comprehensive handling and transparency of decentralized data products. Dehghani recommends starting as simply as possible so as not to delay the development of the Data Mesh architecture.
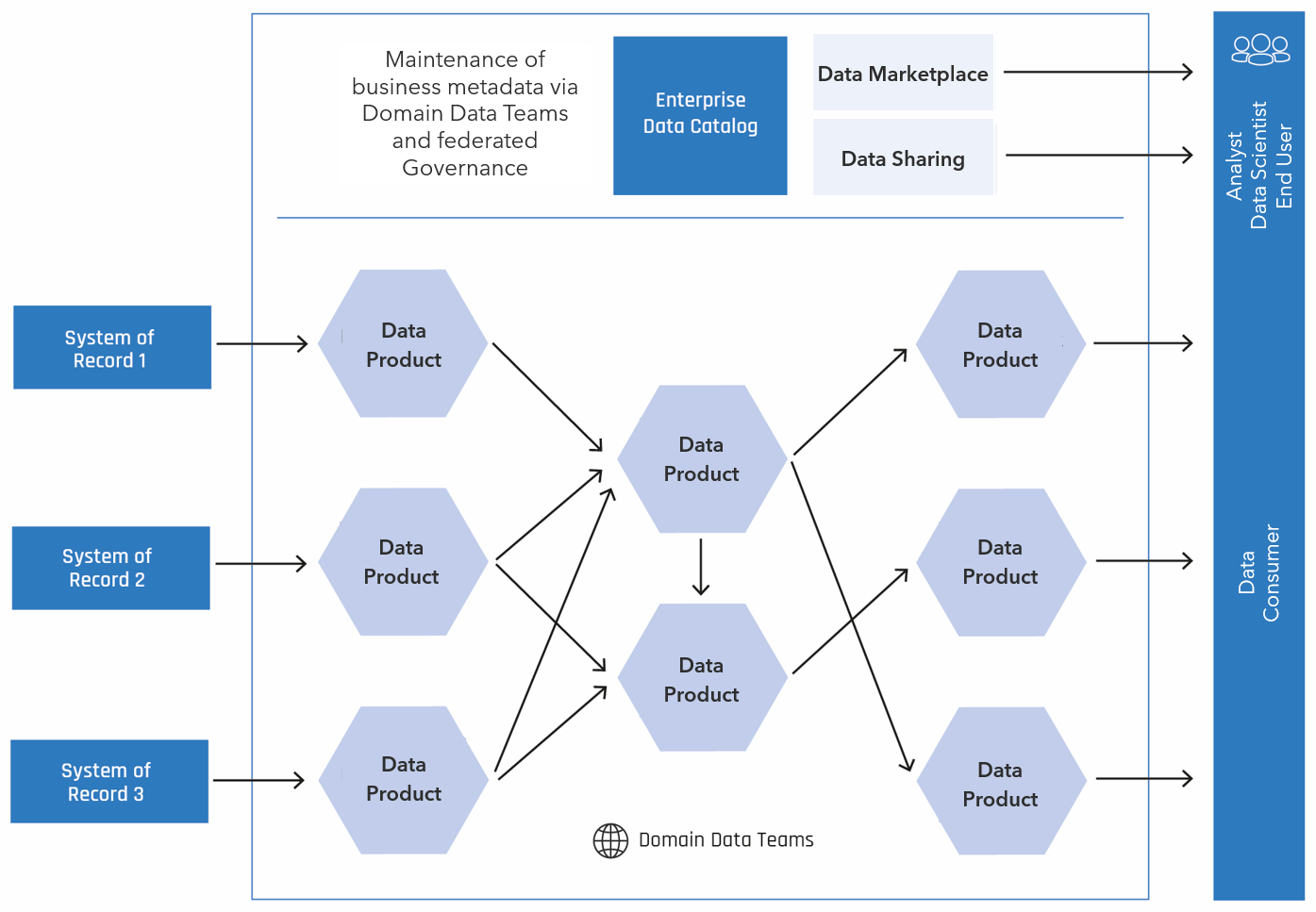
Fig. 1: Basic pattern in the context of a data mesh
In the Data Mesh, the data catalog enables a central directory of all data products that are registered there by the Domain Data Teams. Data sharing functions can in turn be used for easy access. For data consumers, newer developments such as data marketplaces can expand the range of uses to include the monetization of data products or the addition of external data.
The basic principles of a Data Mesh can be supported by these functions as follows:
Domain-oriented responsibility can be supported by defining technical domain structures, communities or focus areas. In addition, overarching interaction can be ensured by defining relationships between data domains.
Federated governance is achieved through clear responsibilities and the common definition of data guidelines, which are implemented through data contracts, for example.
As part of a self-serve platform, data shopping, data sharing or data marketplace functions are provided and integrated into approval processes.
The data product as an elementary building block
In principle, data products should describe themselves as far as possible and provide automatically generated information on the use of the data product. Therefore, a lightweight metadata approach such as data contracts can initially be seen as fulfilling the purpose of finding data and supporting data governance. Data catalogs are suitable for supporting the Data Mesh approach and the properties of data products:
Findability - A simple and intuitive search across all data products in the Data Mesh helps data consumers to use the data products on offer
Addressability - Support through direct access to data sources, the mapping of API endpoints or the traceability of the original origin via data lineage, as well as process support for access requests
Trustworthy - By analyzing the origin and applied business logic via data lineage, as well as automatically derived data quality indicators, trust can be strengthened and the data producer can be supported in achieving its service level goals
Self-describing - Ideally, the self-describing semantics of the data products can speed up use by the data consumer and simplify registration in the data catalog
Each domain and each data product can have its own data catalog function, as already described for the Data Lakehouse. As the main catalog, the enterprise data catalog would obtain the metadata from the domains or data products and thus use the catalog-of-catalogs pattern.
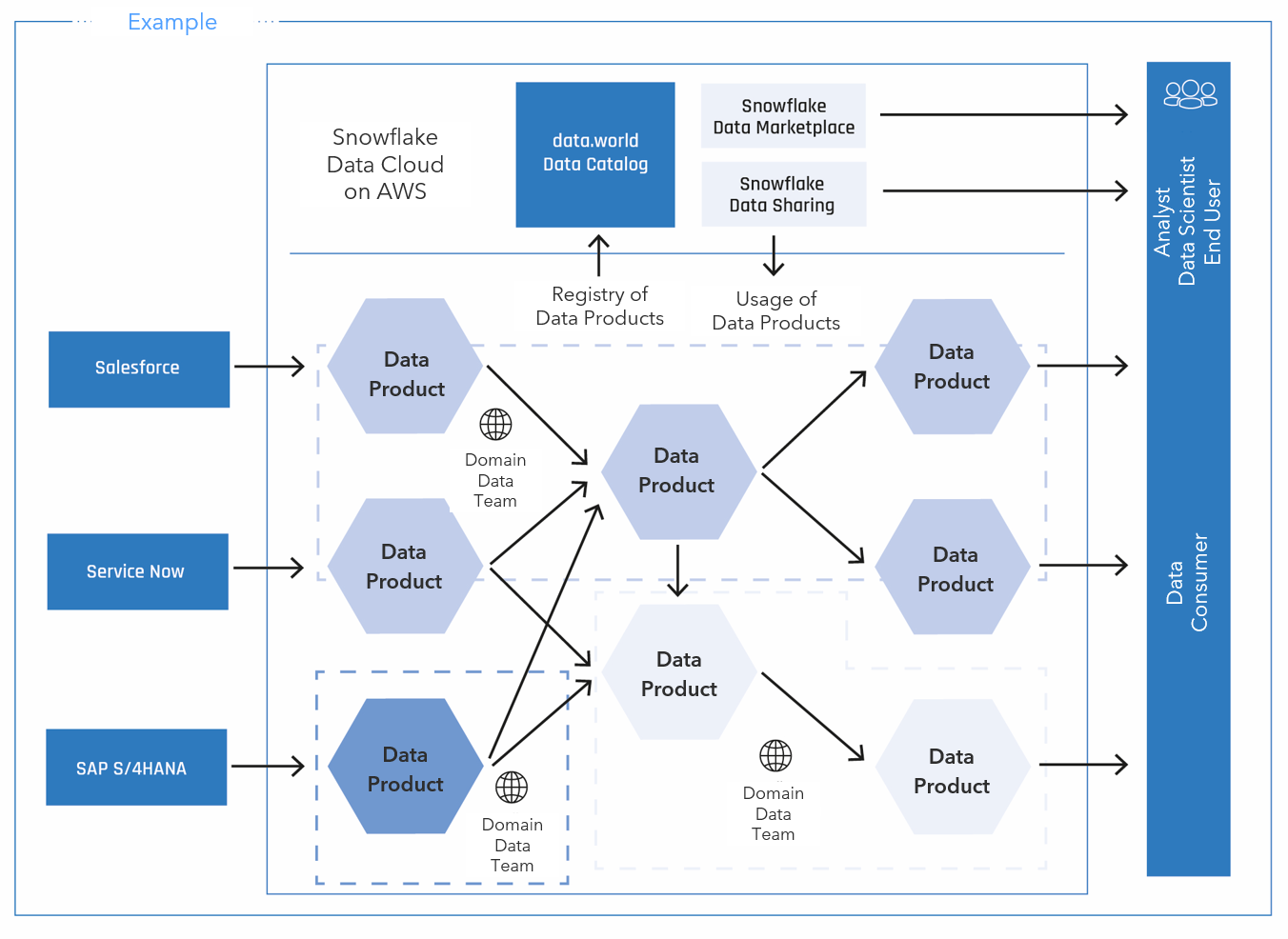
Fig. 2: Practical example of a data catalog and extended functions in the Data Mesh
The data mesh approach is still young and it remains to be seen what type and scope of capabilities will prevail. In principle, the data catalog here has some similarities with its use in the context of a Data Fabric and can further improve the benefits when used together.
This blog is part of the blog series Data Catalogs in different Data Architectures.