
Data Catalog for Data Warehouse and Data Lakehouse
Basic pattern for Data Catalogs

Data Warehouse, Data Lake and Data Lakehouse can be considered as basic centralized data architectures. These can be used in higher-level data architecture patterns such as data fabric and data mesh to optimize the use of data in complex environments. While the Data Warehouse is here for decades and made use of technical metadata since a long time, the Data Lake concepts coined in 20101, produced many data swamps over the time, due to his raw state of data and missing metadata.
The Data Lakehouse can be seen as a relatively new, evolutionary step of the data lake concept. This approach is characterized by the combined capabilities of data warehouse and data lake and thus simplifies data infrastructures and promises to offers the best of both worlds, among other things by making use of metadata via open table formats. As an example platforms like Databricks make use of metadata with Delta Lake and have a strong connection to the idea of a (meta)data catalog2.
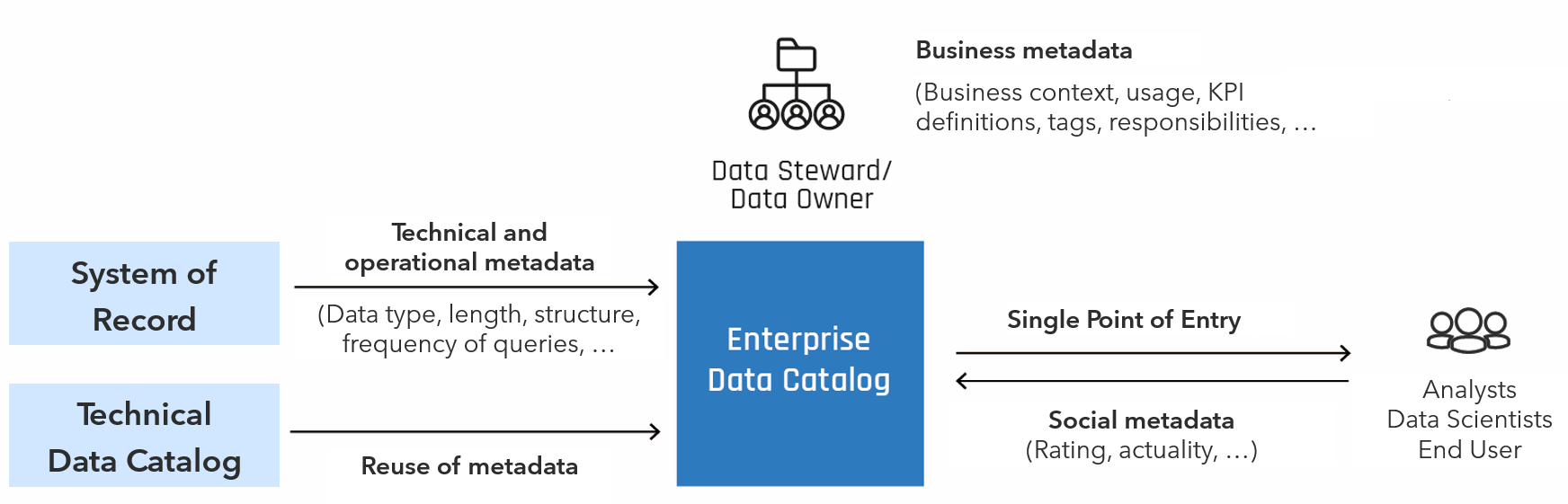
Fig. 1: Basic pattern in the context of data lakehouse architectures
Even if direct access to the Data Warehouse, Data Lake or Data Lakehouse is still an option, the typically more technical data catalogs integrated into the respective platform facilitate the provision and preparation of metadata.
Observations in practice
The platform-integrated data catalogs create transparency about the data in their local context and support platform-specific functions and integration with other platform services. The focus here is on understanding the data structures, the origin of the data, the traceability of calculations and transformations via data pipelines and ETL processes. Another important aspect of technical data catalogs is the close integration with the authorization concept of the data lakehouse, another building block for data governance. Ideally, the enterprise data catalog integrates the metadata that has already been collected and provides a cross-system view for a broad user base.
An exemplary practical scenario could look like this:
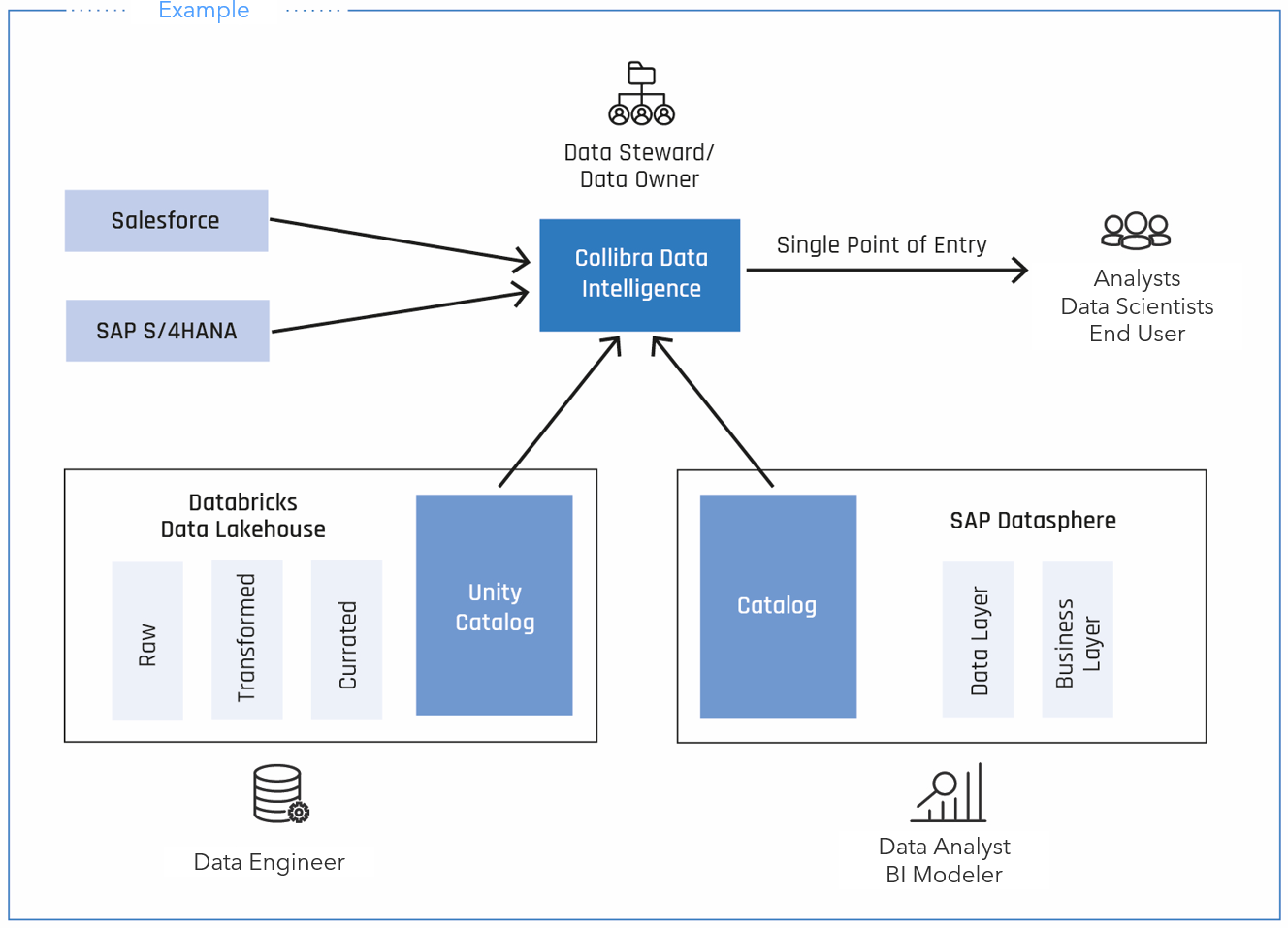
Fig. 2: Scenario for catalog-of-catalogs with integrated data catalog solutions
The idea of the catalog-of-catalogs described above is fundamentally not optimal and initially appears redundant and complex, but in the best case it supports the various roles and, with good integration of the metadata, leads to a congruent view of the metadata and thus the data in the company. In this way, technical roles such as data engineers, data warehouse modelers and administrators are optimally supported by an integrated data catalog. For business roles such as end users, analysts or data stewards, the central enterprise data catalog can provide a comprehensive view across different systems, a technical and business understanding and integration into data governance processes such as data access requests.
Solutions specialized in certain providers such as SAP solutions or in functions such as data lineage are also frequently found. These then often offer an interface or metadata API for accessing the data. The catalog-of-catalogs can make sense here in order to make this metadata usable in the enterprise data catalog.
In a context in which the data lakehouse represents the central analytical platform in the company, the integrated, technical data catalog may well be sufficient for data transparency and basic data governance functions.
This blog is part of the blog series Data Catalogs in different Data Architectures.
First mention of Data Lake: https://jamesdixon.wordpress.com/2010/10/14/pentaho-hadoop-and-data-lakes/
Good insight of Metadata Catalogs vs. Data Catalogs: https://www.linkedin.com/pulse/state-data-catalogs-2023-battle-your-metadata-tom-nats-jbome/