
Data Stack Migration - Case Study
What to consider if you want to go from on-prem legacy to cloud future

To migrate your over years grown and optimized data stack into a new world is a challenge on it’s own:
You have to rewire while need to operate your legacy data stack
You often just change tech but add no value for users who need to test and validate
New tech means new potential but typically it is not just there, you have to change your design for benefits
Capacity for new topics is often blocked during migration period
Every environment and technology is unique and needs careful considerations.
I already wrote about migration in a SAP context, if this is interesting for you:

A current trend for migration - as for nearly everything at the moment - is to support it with AI. This can mean:
Deriving lost tribal knowledge from structural data and metadata from your current stack, usage pattern and stale documentation e. g. by using Graph RAG to connect the dots
Making data stack knowledge easily available for requirement and data engineer vie aa chatbot to understand the situation and ask the right questions to add it to the context
Help to automate design for the new data platform even if you using new implementation patterns to leaverage e. g. cloud native capabilities and advantages
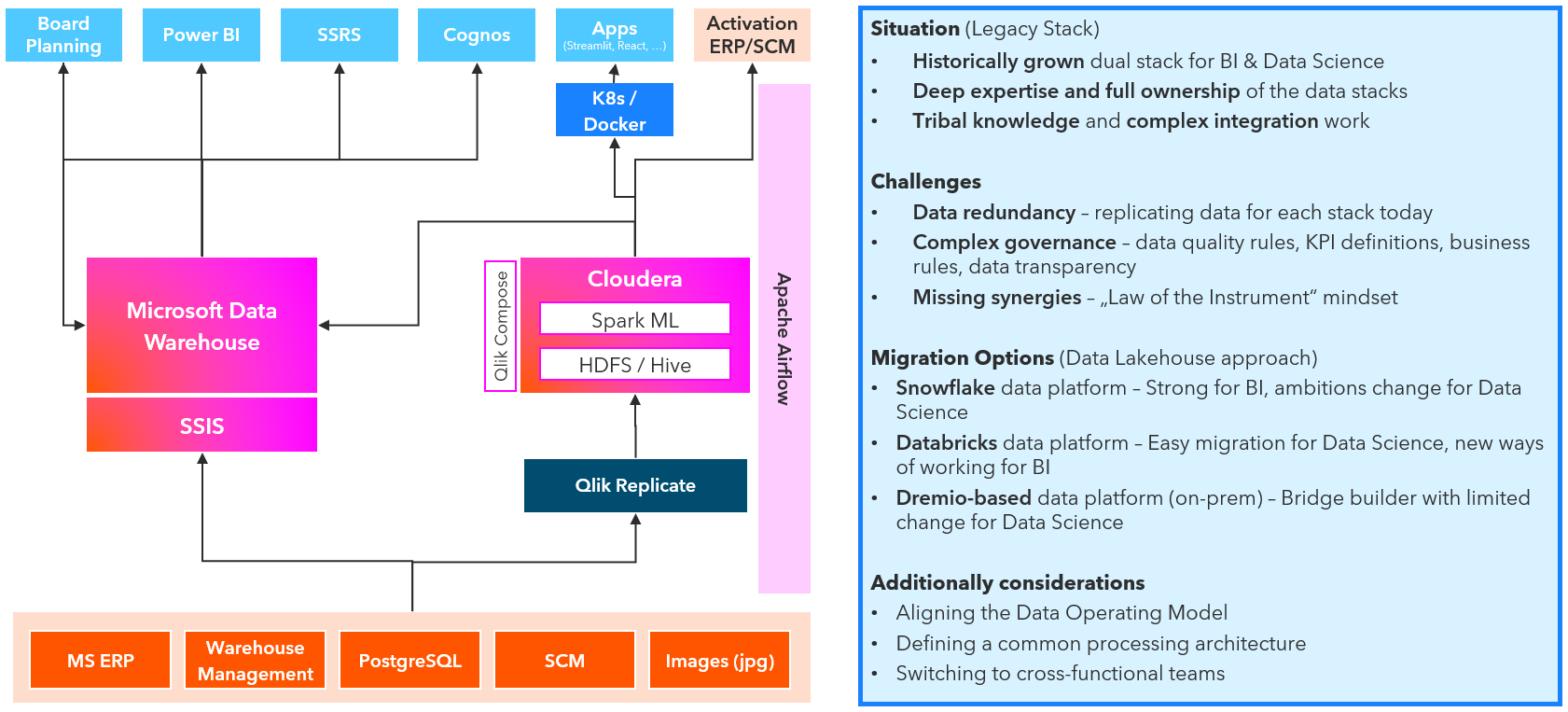
The case shows a two loosely coupled data stacks, historically build in different departments striving for synergies and faster execution. You could say for such situations the Lakehouse pattern was invented for this.
You could easily pick a current technology like Microsoft Fabric or based on Google Cloud Platform. Databricks coined the term Data Lakehouse and is the benchmark for the approach. But it is not so easy. Just changing the technology will not really bring benefits. You have to design how you work together, how you want to use new possiblities of the target platform and what new cases will need.
Just to give some points discussed during the process of defining a target data architecture:
Cloud, on-prem or even a hybrid data platform - different voices in the company lead to careful discussion about possibilities and eventually to defining an exit strategy from the beginning.
Conway’s Law - if you stay in two teams on the new platform you will still build two different ways of working and building. Building cross functional teams help to design solutions purposeful.
Ready for AI - unifying data is one thing, using new possibilities for governance, semantic layer and context layer to support new AI use cases is today a critical point.
Data delivery from source is half the game - additionally to the data platform we designed a data backbone for operational data integration and real-time data ingestion to decouple and accelerate future data integration reqirements.
Focus on automation - strong orientation on business value and delivering fast means to buy things rather out of the box working well than fine tuning and a long learning curve.
So this could lead to a strongly streamlined target picture for the future data platform like this:
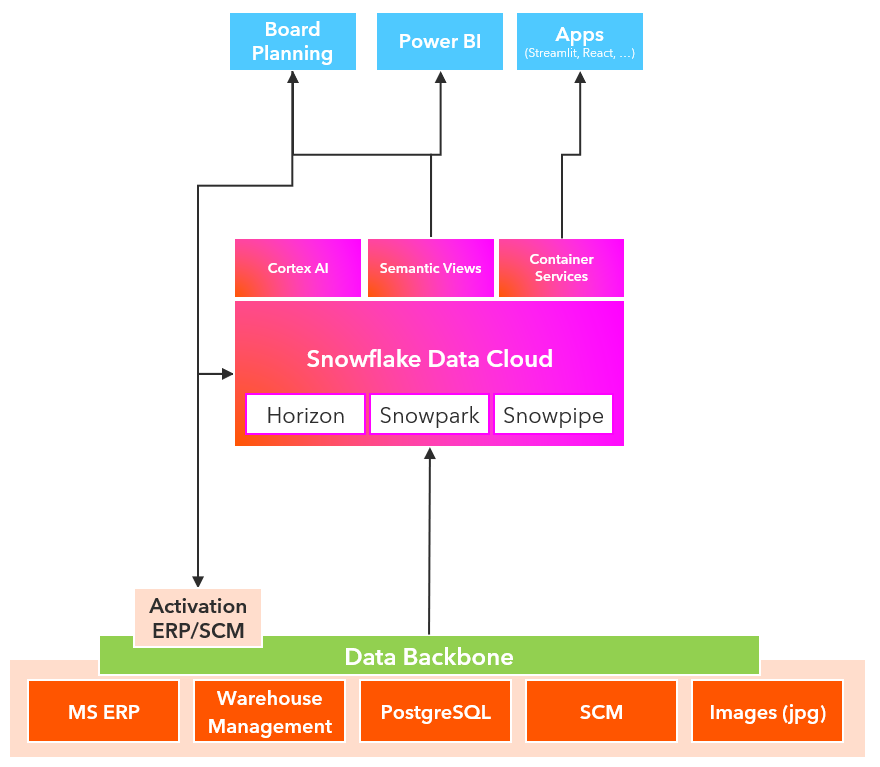
Such a step is not just a tech project for the data team. It is a transformation journey towards business value and fast delivery. This also typically means a lot of change for the data team and possibly the business, too. But if you don’t rethink your way of working on such a step, you will never. Technology won’t change anything if you don’t use it aligned to your companies structures and business strategy.
What are your considerations for migrating your legacy data stack to a future-ready data & AI platform?
I initially considered to include this article as part of my new newsletter about what I experenced and learned over the week. But it got to long so I decided to put it here as a separate article. Feel free to check my newsletter e. g. #3 where I started with a small case study about another architecture.