

Data Catalog for the Modern Data Stack

With the emergence of the first cloud data warehouse offerings such as Amazon Redshift, Snowflake or Google Big Query, the availability of corresponding technology became faster, cheaper and more flexible. Many small, often new providers are driving innovation very quickly and are shaping the idea of the Modern Data Stack through their interaction.
The Modern Data Stack represents an agile mindset and addresses data catalogs in particular with simple, intuitive user interfaces and a high degree of automation. The aim is not so much to obtain the optimized data system landscape from a single source, but rather to achieve optimal adaptation to the company with the available components for the optimal utilization of data.
In the Modern Data Stack, the data catalog1 is usually an independent component that is well integrated with the other services in the environment and offers open interfaces. The data catalog represents the single point of entry to all data activities in the company. This supports the goal of an open data culture and the development of employees' data skills.
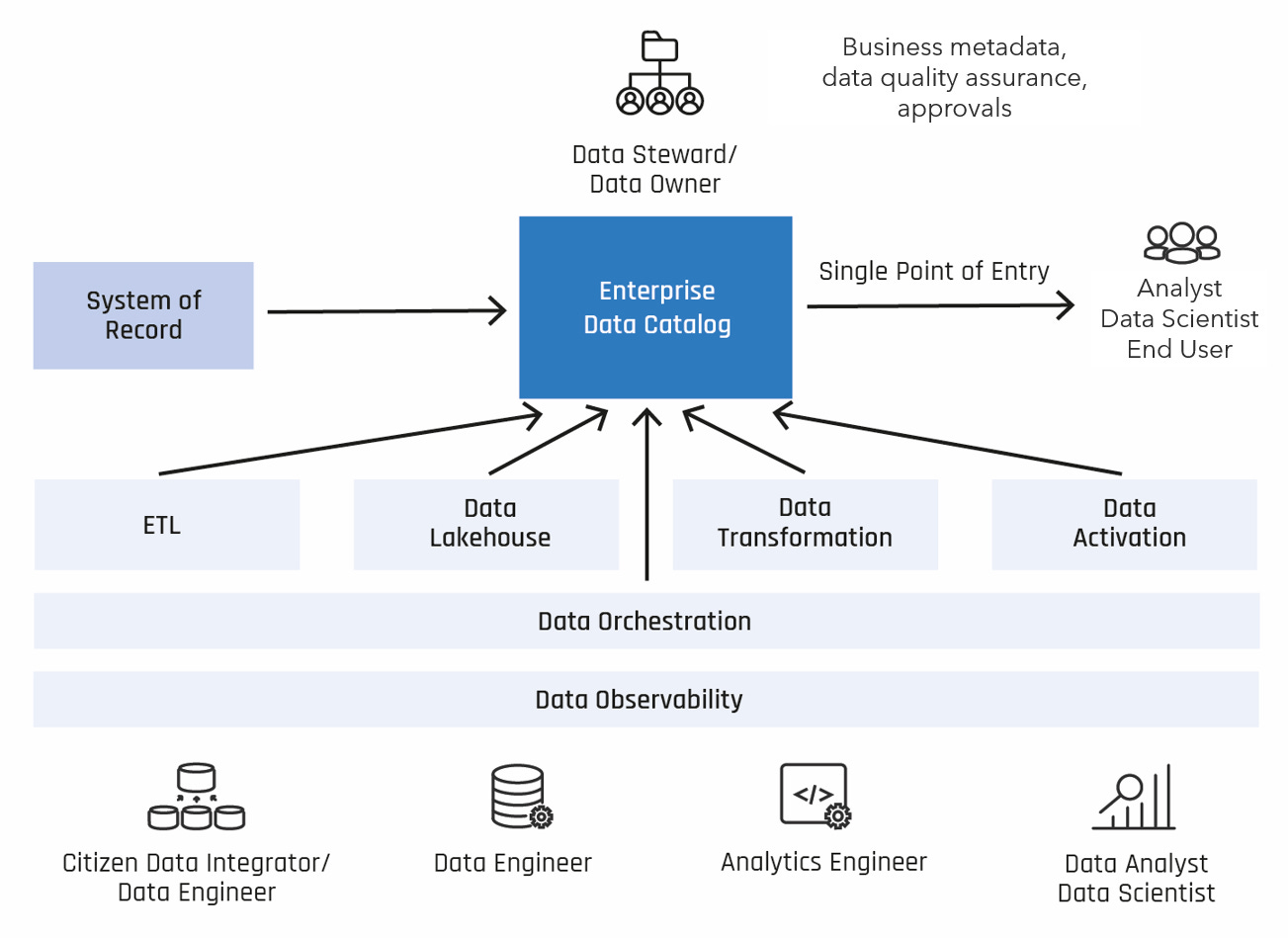
Fig. 2: Basic pattern for Modern Data Stack from a Data Catalog perspective
Hardly any other approach is so representative of the modern, data-driven company. The properties of a data catalog support a wide range of users in their data-related tasks. This enables data to be found, understood and used quickly. Ideally, data stewards and data owners are also supported in their role for flexible data governance in order to provide quick and easy access to data and ensure data quality as well as the quality and availability of technical information on the data objects.
Observations in practice
A typical Modern Data Stack scenario is optimally supported by the data catalog in its modular functions:

Fig 2: Practical scenario for data catalog use in the Modern Data Stack
In the Modern Data Stack, the data catalog is of great importance for self-service analytics along the entire data value chain. New usage scenarios for the data catalog have also emerged here, such as the topic of data observability. Data catalog solutions already provide support today by integrating data quality functions into their data lineage and thus contribute to the rapid detection and correction of errors in data provision.
This blog is part of the blog series Data Catalogs in different Data Architectures.
Depending on your needs there are possible alternatives like a semantic layer as discussed here: https://www.linkedin.com/pulse/stop-emphasizing-data-catalog-guy-fighel/, but we have to be aware there are a broad spectrum of data catalogs and other sulutions leaveraging metadata for business.